
Narges Bani Asadi is a founder and CEO of Bina Technologies.
We are at the dawn of a new age of personalized medicine.
Just as Moore’s law transformed computing — and, as a result, all aspects of our professional and personal lives — so, too, will the interpretation of the human genome transform medicine. We are moving from the inefficient and experimental medicine of today towards the data-driven medicine of tomorrow. Soon, diagnosis, prognosis, treatment, and most importantly, prevention will be tailored to individuals’ genetic and phenotypic information.
As we enter the second decade of the 21st century, investments in molecular biology, bioinformatics, disease management and the unraveling of the human genome are all finally bearing fruit. Personalized medicine promises to revolutionize the practice of medicine, transform the global healthcare industry, and ultimately lead to longer and healthier lives.
The urgent need for personalized medicine
The need for personalized therapies abound, as a recent WSJ article emphasizes. Right now, two of the immediate applications for personalized medicine are cancer diagnostics and newborn screening.
This year, over 580,000 Americans — 1,600 people per day — are expected to die of cancer. Similarly grim numbers can be found with newborn medical care: One in 20 babies born in the U.S. are admitted to the neonatal intensive care unit (NICU), and 20 percent of infant deaths are a result of congenital or chromosomal defects.
Both of these trends can be fixed with the rise of personalized medicine, which is a classic technology-based transformation. The digital information age was made possible by fundamental advances in semiconductor technology, which in turn drove down computing costs. Processing speeds have continually doubled every two years and applications have long since exploded, making the trend ubiquitous.
With DNA sequencing, technology advances are happening even more rapidly. Processing power is doubling every six months, and decreasing costs and increasing speeds have made it far easier to discover links between DNA sequence variations and human disease.
 Several key things need to happen in order for us to make major headway, however. The collection, processing, and storing of molecular information will become a new and significant driver of demand for information technology. While publicity helps spur investment and capture the public imagination, the underlying science behind personalized medicine is what will ultimately allow us to make good a long-held promise.
Several key things need to happen in order for us to make major headway, however. The collection, processing, and storing of molecular information will become a new and significant driver of demand for information technology. While publicity helps spur investment and capture the public imagination, the underlying science behind personalized medicine is what will ultimately allow us to make good a long-held promise.
This TIME magazine cover from a few weeks ago articulates the enthusiasm with which we have taken up the mantle of genome-driven therapy — but it’s nothing new.
Supporters have been talking about the promise of DNA for a long time. Check out this TIME cover from 1971, or this one from 2003. Cost and complexity have been the biggest bottlenecks in the process so far, but we are closer now than we have ever been to harnessing the power of DNA-based therapies.
Here are the key technological and medical advances that we believe need to happen if the vision of personalized medicine is to hold true.
Ultrafast, accurate and low-cost DNA sequencing
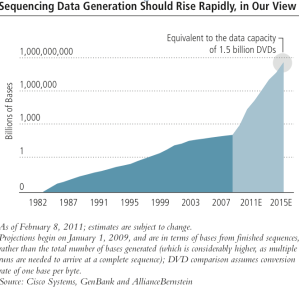
Ever since the $3 billion, 13-year Human Genome Project jump-started a new industry in 1990, we have seen a revolution in DNA sequencing throughput and cost. Moore’s law is nowhere on display as clearly as it is in the sequencing market.
Recent innovations in sequencing technologies have dramatically cut the time it takes to work through an entire genome to less than twenty-four hours. Today’s sequencing instruments not only perform the chemistry of sequencing, but they also perform the initial conversion to raw sequenced data, a process commonly known as primary analysis.
![]()
Additionally, today’s sequencing instruments dramatically lowered the cost of sequencing to within $5,000 per genome. In fact the cost of sequencing is no longer prohibitive and many U.S. citizens have said they would be willing to pay out-of-pocket for whole-genome sequencing (WGS). The key breakthrough here is being able to have entire genomes sequenced in under a few hours and at affordable rates.
But the minimum threshold is practically here: We’re very close to sequencing an entire human genome forty times over in less than a day, with an error rate of less than one in a million in the raw reads. This is why people are excited about personalized medicine. We’re at an inflection point.
Estimated arrival date: Immediately
Companies to watch: Illumina, Life Technologies, PacBio, Oxford Nanopore, Complete Genomics
Rapid, low-cost, and accurate secondary analysis
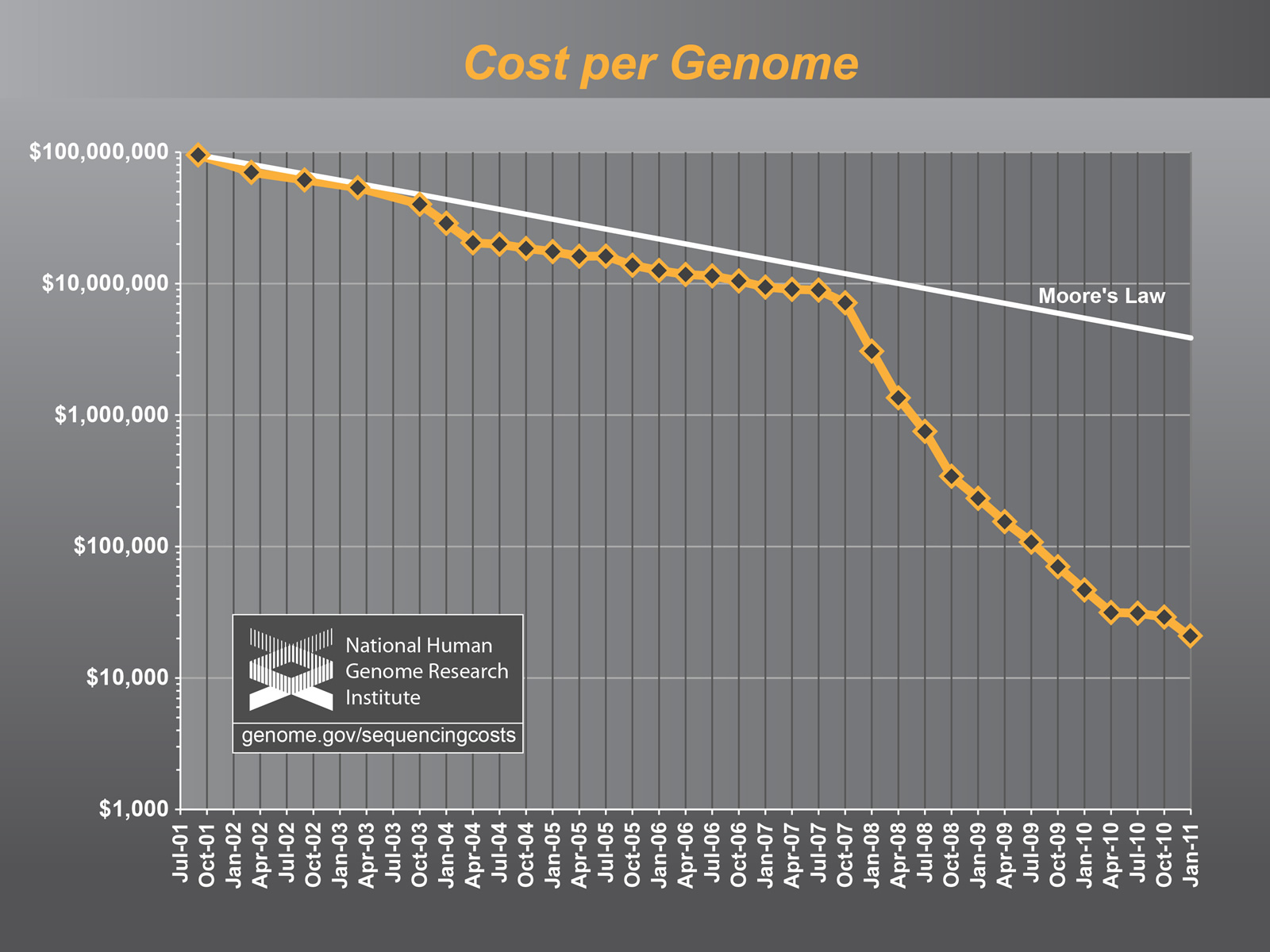
Elaine Mardis, Director of the Genome Institute at Washington University once mused that while the cost of genome sequencing has plummeted, the cost of the subsequent data analysis has not kept pace. The challenge is threefold: Analysis needs to be fast, cheap, and most importantly, accurate.
Once a genome is sequenced, it must be assembled into a complete genome. This assembly, commonly known as secondary analysis, is typically done using supercomputers and takes several days to complete. During secondary analysis, raw reads are assembled to form a complete genome, allowing scientists to from a complete picture of an individual’s genetic variations.
Imagine putting together a jigsaw puzzle that has a billion pieces. That’s exactly what secondary analysis does.
Because this step requires a supercomputer, infrastructure, and trained bioinformaticians, the costs for secondary analysis are significant. When you factor in the cost of the supercomputers, the supporting physical infrastructure, the system administrators and the bioinformaticians, secondary analysis can reach into the $10,000’s per genome analyzed.
Fortunately there are emerging disruptive technologies that are able to take raw reads off sequencing machines and assemble finished genomes more quickly and at scale. The key breakthrough here is being able to assemble a complete genome in under a few hours, with high accuracy, and at low cost.
And then there’s the data question. While sequencing a single genome creates terabytes of raw data, data from assembled genome that has gone through secondary analysis cuts that data a thousandfold to merely gigabytes.
As a result, secondary analysis is also the area in which big data, high-performance computing, and genomics really start to overlap. Recent innovations in the former two categories are what make secondary analysis possible in four hours or less.
Estimated arrival date: 3-6 months
Companies to watch: Bina Technologies, DNAnexus, RealTime Genomics, Broad Institute, Academic Institutions
Connecting the dots between genetic mutations and disease
 Completed genomes and their identified genotype then need to be interpreted for biological relevance. This step is commonly called tertiary analysis. This is where a certain mutation (or set of mutations) is matched with a certain disease or physical trait (phenotype).
Completed genomes and their identified genotype then need to be interpreted for biological relevance. This step is commonly called tertiary analysis. This is where a certain mutation (or set of mutations) is matched with a certain disease or physical trait (phenotype).
In a genome of a billion bases, it is estimated that each one of us has roughly 10 million single nucleotide variants (SNVs). Each SNV alone or in combination can have negligible to extraordinary effects on our normal biological function. The challenge is to find those SNV’s that have an impact on biological function and then prescribe a treatment strategy. It’s like looking for a needle in a haystack.
This is a big data problem. To make matters worse, there are no standard processes for how this analysis needs to happen. Establishing a standard process and putting some real horsepower behind it will make it possible to perform effective, timely tertiary analysis.
Essentially, we have to create software tools to enable scientists and clinicians to extract maximum biological meaning from complex genomic data (think: Palantir for genomics). The key breakthrough here is the ability to identify specific disease phenotypes that are linked to specific genotypes — connecting specific mutations to specific markers — in a repeatable way.
Up until now the majority of genomics variations have remained uninterpreted and the so-called look-up table that links our genetic variations to actionable information has been very sparse.
This is a chicken and egg problem. We need to sequence more genomes and put them in the context of disease population studies to learn more. The good news is the unveiling of several very large scale genomics projects — including the Million Veteran Program and the UK’s 100K Genome Project — provide massive new datasets for discovering and building ever-growing knowledge of genome interpretation.
Whoever puts the power of tertiary analysis into the hands of those who need it most will be in a very strategic position to capitalize on the multi-billion dollar opportunity that personalized medicine ultimately represents. This is about creating an industry standard.
The payoff? These toolsets can be used to support clinical trials and develop comprehensive genetic test panels, which in turn make medical interpretation possible.
Estimated arrival date: 6-18 months
Companies to watch: Bina Technologies, NextBio, Ingenuity, Knome, Station X
Injecting genetic information into medical care
Now that you have theoretically sequenced the patient’s genome, and identified the list of candidate mutations, the next step is to combine this knowledge with other medical factors — the patient’s history, environment, family background, microbiome, diet, etc. Improving patient care and developing personalized therapies depends on intelligently leveraging complex molecular and clinical data from a variety of internal, external, and public sources. The key innovation at this juncture is mainly cultural.
Genomic data needs to be integrated with patient health records so that it can be interpreted by trained physicians who can put genomic insights in wider context. The goal is nothing less than redefining disease at the molecular level and integrating this data with patient histories.
The end result? Clinical researchers can translate novel biomarkers and drug responses into improved treatments, which in turn can be tailored to each patient’s genome.
The challenges here are several. Again, there are no standard protocols for pulling this information together in a common environment. Today, too many databases exist in isolation and are not cross-mineable. Even basic availability is an issue, not to mention structure, formatting, and method of data delivery. There will need to be a lot of integration before we’re able to put all of the information at a researcher’s fingertips simultaneously.
More importantly, today’s physicians are not yet widely trained to interpret genomic information. Fortunately, this is a problem that can be solved with education and profitability.
Roughly 100 years ago, a new disruptive technology brought about a new discipline of medicine: radiology. As radiology matured, the x-ray film became a standard, as did its underlying formats. Before long, radiology data had become part of the patient record and medical schools started introducing radiology as part of their physician training program.
The same must happen with genomics data, which must be standardized before it is effectively utilized. The practice of medicine must likewise introduce new training methods to prepare the next generation of doctors to leverage genomics.
As such, we quickly move from investigating the genome and researching disease to actually developing diagnostics and insights into therapies.
Accordingly, regulatory approval will be necessary for any such resulting therapy — a further but ultimately surmountable hurdle.
Estimated arrival date: 12-36 months
Companies to watch: 23andMe, InVitae, Personalis
Getting the big guys to pay for it
The final step in making personalized medicine a reality is implementation. The practice of healthcare should change dramatically as new therapies and approaches redefine the roles of hospitals and physicians.
The hurdle here is one of creating favorable economics, which can cement whole genome sequencing (WGS) as a standard of care. Payors and medical insurers have to include WGS as part of their reimbursement program.
We’re already beginning to see the benefits of genome sequencing in public health. The widely publicized account of Nic Volker’s recovery in 2011 captured the public’s imagination in a way that genomics had never done before.

Numerous scholarly articles are trickling in, touting the benefits of WGS and how it can cut healthcare costs and improve outcomes. As these cases become the norm rather than the exception, insurance companies will inevitably be forced to pick up the tab.
Recently Wellpoint, one of the nation’s largest payors, has hinted that it will approve reimbursements for Sequenom’s MaterniT21 Plus fetal genetic screening tests. Anthem Blue Cross has agreed to reimburse AlloMap’s genetic testing in Stable Heart Transplant Patients — a big step. Even lab testing giants LabCorp and Quest Diagnostics have been openly bullish on the genomics revolution and have signed numerous partnership agreements with innovative genomics companies.
Payors and providers will likely rely on molecular information to manage scarce healthcare resources. The second major impact will arise from incorporating molecular information into drug discovery and development.
The blockbuster drug model will be redefined. Disparate disorders could actually be caused by similar molecular mutations, so drugs that have a common molecular target but appear to treat seemingly disparate diseases will emerge. Perhaps the most significant impact will come from the rise of synthetic biology, the process of directly manipulating, engineering, and manufacturing cells. Synthetic biology will redefine how researchers study disease and test drugs during preclinical development.
Big payors and pharma companies will be properly motivated by both new profits and major cost savings. It is reasonable to expect that personalized medicine will be a dominant conversation on a national stage, as outcomes dramatically improve and personalized medicine becomes the locus of medical innovation for a decade or more.
Estimated arrival date: 24-48 months
Companies to watch: Kaiser, VA Hospital, Merck, GSK, Genomic Health, Genentech, Lab Corp, Quest Diagnostics, Roche
The revolution is coming
Here’s a simple chart spelling out the phases of escalation as the genomics landscape matures and draws closer to realizing our long-held vision of personalized medicine.
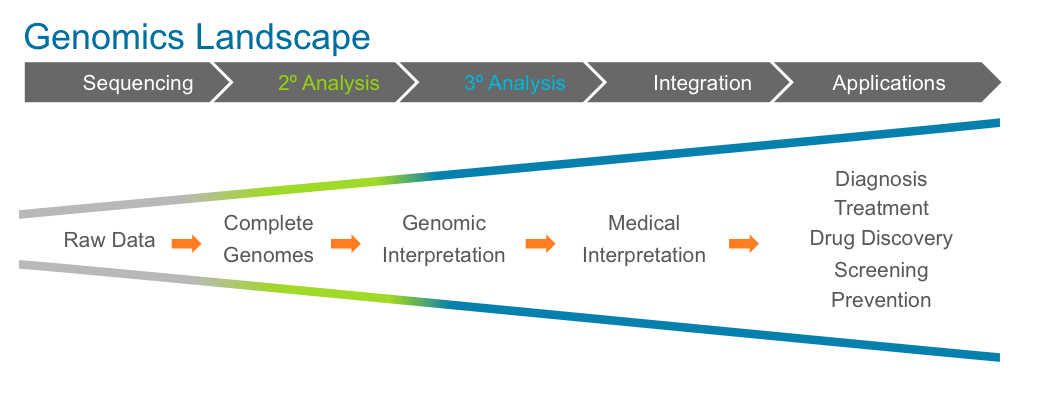
It should be pointed out that sequencing — the term most familiar to an everyday consumer — is no longer the locus of innovation. That’s a good thing.
That sequencing has evolved to the point it is at today is nothing less than extraordinary. Sequencing is suddenly cheap, and fast. As a result, sequencing will soon be a commodity however, and the amount of genomic data on our hand is about to multiply by an order of magnitude.
Talent and investment dollars have already started to flow downstream in an effort to address the challenges that cheap and fast sequencing has itself created — namely, taking piles upon piles of data and deriving insights from that pipeline raw material .
There’s a huge opportunity right now, again, at the intersection of high-performance computing, big data, and genomics. I am eager to see these worlds continue to collide, and at increasing speed and frequency. Personalized medicine is closer than you think, but only as a multidisciplinary approach takes hold.
Narges Bani Asadi is a founder and CEO of Bina Technologies. Bina is working to commercialize years of multidisciplinary research at the intersection of systems biology, big data, high performance computing, and genomics. Narges holds a Masters and a Ph.D in Electrical Engineering from Stanford University.

