
Want smarter insights in your inbox? Sign up for our weekly newsletters to get only what matters to enterprise AI, data, and security leaders. Subscribe Now
Diarization — the process of partitioning out a speech sample into distinctive, homogeneous segments according to who said what, when — doesn’t come as easy to machines as it does to humans, and training a machine learning algorithm to perform it is tougher than it sounds. A robust diarization system must be able to associate new individuals with speech segments that it hasn’t previously encountered.
But Google’s AI research division has made promising progress toward a performant model. In a new paper (“Fully Supervised Speaker Diarization“) and accompanying blog post, researchers describe a new artificially intelligent (AI) system that “makes use of supervised speaker labels in a more effective manner.”
The core algorithms, which the paper’s authors claim achieve an online diarization error rate (DER) low enough for real-time applications — 7.6 percent on the NIST SRE 2000 CALLHOME benchmark, compared to 8.8 percent DER from Google’s previous method — is available in open source on Github.
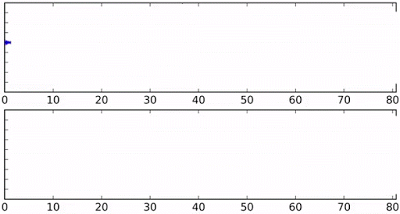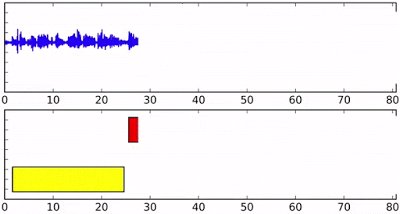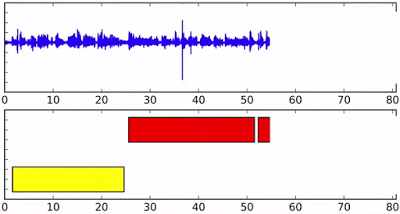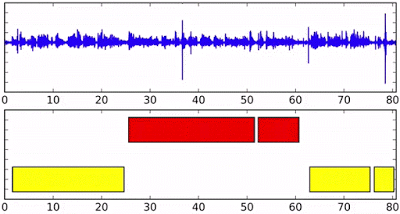
Above: Speaker diarization on streaming audio, with different colors in the bottom axis indicating different speakers.
The Google researchers’ new approach models speakers’ embeddings (i.e., mathematical representations of words and phrases) by a recurrent neural network (RNN), a type of machine learning model that can use its internal state to process sequences of inputs. Each speaker starts with its own RNN instance, which keeps updating the RNN state given new embeddings, enabling the system to learn high-level knowledge shared across speakers and utterances.
AI Scaling Hits Its Limits
Power caps, rising token costs, and inference delays are reshaping enterprise AI. Join our exclusive salon to discover how top teams are:
- Turning energy into a strategic advantage
- Architecting efficient inference for real throughput gains
- Unlocking competitive ROI with sustainable AI systems
Secure your spot to stay ahead: https://bit.ly/4mwGngO
“Since all components of this system can be learned in a supervised manner, it is preferred over unsupervised systems in scenarios where training data with high quality time-stamped speaker labels are available,” the researchers wrote in the paper. “Our system is fully supervised and is able to learn from examples where time-stamped speaker labels are annotated.”
In future work, the team plans to refine the model so that it can integrate contextual information to perform offline decoding, which they expect will further reduce DER. They also hope to model acoustic features directly, so that the entire speaker diarization system can be trained end-to-end.

