Data is a powerful storytelling source. We often uncover new truths, undiscovered trends, even potential warnings when using data to tell a story. But as powerful as data can be, it can also be misleading and filled with bias.
Here’s what experience teaches about the pitfalls of biased data analysis, and how we can protect ourselves as researchers and analysts:
[aditude-amp id="flyingcarpet" targeting='{"env":"staging","page_type":"article","post_id":2785870,"post_type":"community","post_chan":"none","tags":"category-business-industrial-business-operations","ai":true,"category":"none","all_categories":"ai,data-infrastructure,datadecisionmakers,","session":"C"}']Focus on the context around the data set
Data sets can tell a wide variety of stories, but accurate stories are achieved only when context is considered. Analyzed against a particular backdrop, data can tell a specific tale. But if that backdrop inaccurately reflects the captured data, the resulting story will be misleading, if not false.
Take for example, our recent data analysis associated with the Super Bowl. The objective for this was to uncover how Super Bowl commercial ad spend impacted advertisers’ overall ad spend behaviors. We approached this by analyzing our proprietary data around advertising transactions in the weeks leading up to the most watched American sporting event.
AI Weekly
The must-read newsletter for AI and Big Data industry written by Khari Johnson, Kyle Wiggers, and Seth Colaner.
Included with VentureBeat Insider and VentureBeat VIP memberships.
Since Super Bowl advertisers are a small sampling of our total advertiser pool, it became imperative to avoid extrapolating or generalizing these behaviors en masse to other one-off events or other advertisers. We couldn’t speculate, for example, that the results of this analysis would also hold true for the World Cup or a boxing match with varying levels of online viewership. Results indicated that the use of private marketplaces (PMP) rose notably, week-over-week, three weeks prior to the Super Bowl. Within that period, 38% of PMP spending concentrated almost exclusively on Super Bowl week. This makes sense as PMPs provide publishers more control over which buyers have access to their audiences and inventory.
These behaviors centered on this particular event, within a specific advertiser segment: advertisers advertising during the Super Bowl via digital campaigns. If we ignored that context, we would be dismissing the nuances uniquely associated with the Super Bowl. In this case, digital consumption remains nascent and mostly consumed on linear TV – and the results clearly reflected this.
Be aware of your sample bias
While nipping sample bias in the bud is generally a good rule of thumb, it’s not always possible. Being mindful that sample bias exists is critical for understanding data results and ultimately the story the data wants to tell. If the data skews towards one sample result, the data story will almost certainly point to that bias. Without acknowledging that concept, or taking it into consideration, the story will ultimately be flawed.
In our Super Bowl analysis, a strong temptation emerged to analyze advertisers’ spending behavior by boxing them into vertical categories to understand why, for example, retail behaved differently from automotive advertisers. However, due to this sample’s unique nature, this was not achievable. There were significantly more automotive, food & drink and personal finance advertisers during the Super Bowl than other categories to make a fair comparison. Instead, we analyzed the data across platforms and channels, reaching several key conclusions.
Mobile web ad share spending fell prior to the Super Bowl in favor of increased connected TV (CTV) spending, then sharply returned to average levels during Super Bowl week. Lastly, while overall digital ad spend remained fairly consistent, ad spend impacted execution through the Super Bowl, as noted above with PMP usage. By analyzing the data across platforms and channels instead of industries, we were able to avoid a framing bias due to the narrow sample of categories. While the data was rich enough to be dissected across platforms and channels, one thing we kept in mind was that the set of Super Bowl advertisers were still skewed towards a concentrated set of industry categories.

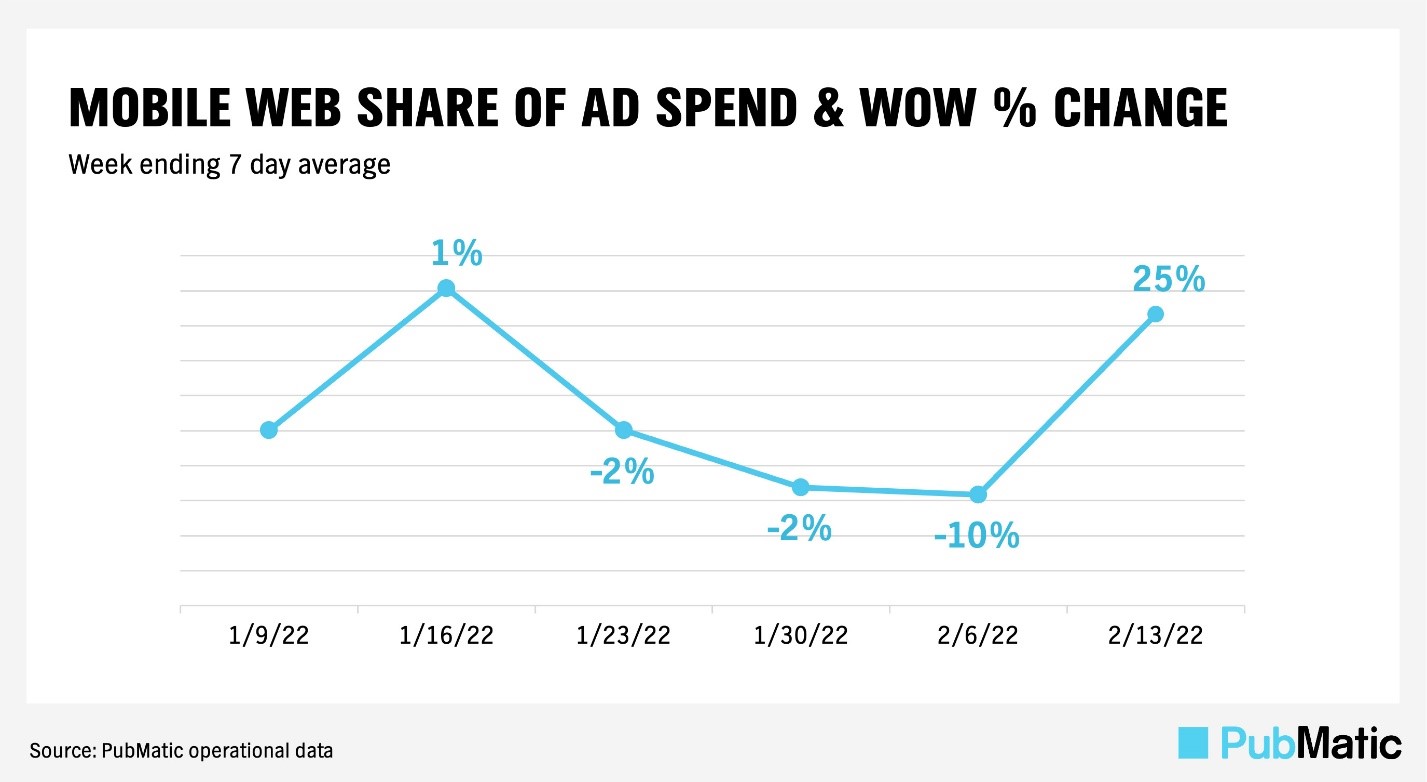

In short, analyzing data at narrow granularities may present faulty interpretations and misleading conclusions in future decision making.
[aditude-amp id="medium1" targeting='{"env":"staging","page_type":"article","post_id":2785870,"post_type":"community","post_chan":"none","tags":"category-business-industrial-business-operations","ai":true,"category":"none","all_categories":"ai,data-infrastructure,datadecisionmakers,","session":"C"}']
Explore the data with an open mind
Many researchers carry out analyses with a predetermined idea or hypothesis. By strictly seeking out data that supports a hypothesis, a confirmation bias will inevitably lead you astray. The goal isn’t to prove a hypothesis correct; the goal is to uncover the truth. The hypothesis simply serves as the testing ground.
When we started gathering the Super Bowl data, it made intuitive sense to believe that digital advertisers would reduce online spending in favor of linear TV due to the weight of the latter’s historical importance during the Super Bowl. However, this proved surprisingly untrue. The analysis actually uncovered that, while advertisers spent healthy budgets on linear TV, they did not dial back their online presence. Ad spend online in fact remained consistent leading up to the game. Advertisers allocated most of their digital spend during Super Bowl week, due partly to video ad spend, which increased 26% week over week. Had we only reviewed the data with the mindset of proving our assumption, we wouldn’t have uncovered these important results.
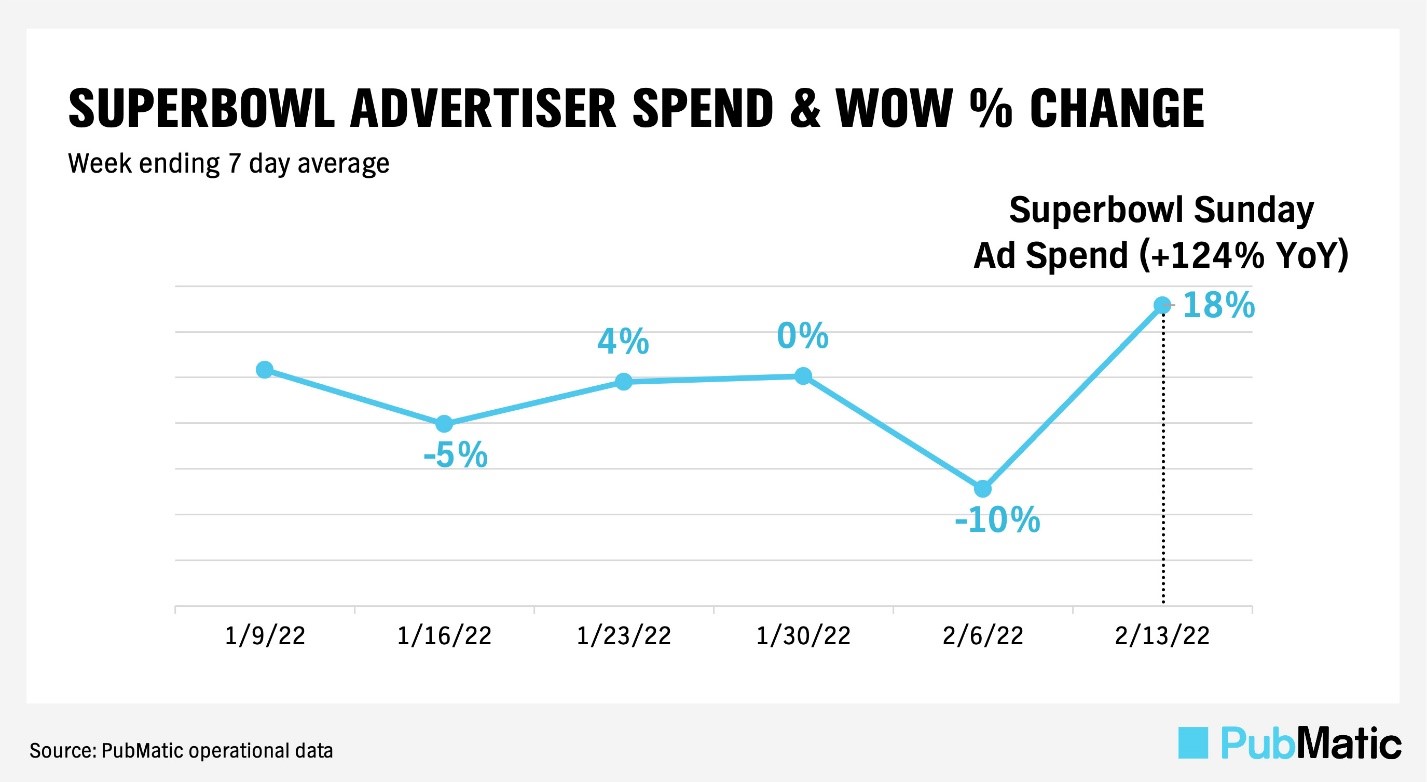
How a data analysis is communicated matters. A single data set can tell a variety of stories, especially when preconceived notions come into play. Like science, data analysis must always contain a hint of skepticism. Otherwise, perfectly sound data becomes vulnerable to bias, ultimately destroying the entire purpose behind accurate data collection and critical decision-making based on that data. Remaining vigilantly mindful of data bias may therefore the most valuable tool to possess throughout the entire data gathering and analyzing process.
Susan Wu is senior director of marketing research at PubMatic.
[aditude-amp id="medium2" targeting='{"env":"staging","page_type":"article","post_id":2785870,"post_type":"community","post_chan":"none","tags":"category-business-industrial-business-operations","ai":true,"category":"none","all_categories":"ai,data-infrastructure,datadecisionmakers,","session":"C"}']
VentureBeat's mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Learn More