
Want smarter insights in your inbox? Sign up for our weekly newsletters to get only what matters to enterprise AI, data, and security leaders. Subscribe Now
Reka, a San Francisco-based AI startup founded by researchers from DeepMind, Google and Meta, is introducing a new multimodal language model called Reka Core. It’s billed as the company’s “largest and most capable model” and is trained from scratch using thousands of GPUs.
Available today via API, on-premise, or on-device deployment options, Core is the third member in Reka’s family of language models and offers the ability to understand multiple modalities, including image, audio and video. Most importantly, despite being trained in less than a year, it matches or beats the performance of top models from leading, deep-pocketed players in the AI space, including OpenAI, Google and Anthropic.
“This ability to train highly-performant models in a very short period makes the company stand out,” Dani Yogatama, the co-founder and CEO of the 22-person company, said in an interview with VentureBeat.

Yi Tay, Reka’s chief scientist and co-founder, wrote on X that the company used “thousands of H100s” to develop Reka Core. And developing something from scratch to rival OpenAI’s GPT-4 and Claude 3 Opus is certainly a feat. He cautions that Core is still improving, but the team is impressed by the performance thus far.
AI Scaling Hits Its Limits
Power caps, rising token costs, and inference delays are reshaping enterprise AI. Join our exclusive salon to discover how top teams are:
- Turning energy into a strategic advantage
- Architecting efficient inference for real throughput gains
- Unlocking competitive ROI with sustainable AI systems
Secure your spot to stay ahead: https://bit.ly/4mwGngO
What does Reka Core bring to the table?
While the exact number of parameters for Reka Core has not been disclosed, Yogatama described it as a “very large model” (the last one, Reka Flash, had 21 billion parameters) trained from multiple sources, including publicly available data, licensed data and synthetic data spanning text, audio, video and image files.
This vast scope of training, he explained, enables Core to understand multiple modalities as input and provide answers across domains such as mathematics and coding with a high level of reasoning. There’s also support for 32 languages and a context window of 128,000 tokens, which allows the model to take in and process vast amounts of diverse information in one go. This is suitable for working on long docs. Yogatama said Core is only the second model after Google’s Gemini Ultra to cover all modalities, starting from text to video, and provide high-quality outputs.
In the perception test for video, Core outperformed its only competitor Gemini Ultra by a decent margin (scoring 59.3 vs 54.3). Meanwhile, in the MMMU benchmark for image tasks, it sat right behind GPT-4 (56.8), Claude 3 Opus (59.4), Gemini Ultra (59.4) and Gemini Pro 1.5 (58.5) with a score of 56.3. Elon Musk’s xAI also recently launched a vision-capable version of Grok, although this model still trails behind competitors with a score of 53.6.
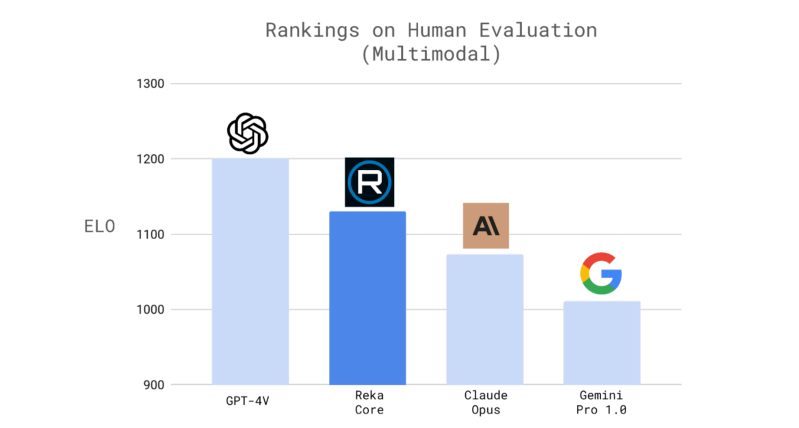
Even in other benchmarks, Core was found to be matching industry-leading players. For instance, in the MMLU test of knowledge tasks, it scored 83.2, sitting right behind GPT-4, Claude 3 Opus and Gemini Ultra. Meanwhile, in the GSM8K benchmark for reasoning and HumanEval for coding, it was able to beat GPT-4 with scores of 92.2 and 76.8, respectively.
To achieve this level of performance in a very short period, Yogatama said the company took an upside-down approach. This means instead of training a model and seeing where it goes, they started with a targeted performance level and then worked their way backward to figure out what should be the best and most efficient way to achieve it, covering aspects like how much data should be used for training and number of GPUs required.
Multiple partnerships in the pipeline
With a focus on all modalities and competitive pricing of $10 per million input tokens and $25 per million output tokens, Reka hopes to unlock new and unique use cases for customers from different industry segments, including e-commerce, gaming, healthcare and robotics. OpenAI’s GPT-4 Turbo, for context, has the same pricing for input tokens but $30 for output.
Reka is still at a nascent stage, but it is going all in to take on the dominance of OpenAI, Anthropic and Google in the AI domain. The startup has already started working with industry partners and organizations to expand the reach of its models. Snowflake, for one, recently announced the inclusion of Reka Core and Flash in its Cortex service for LLM app development. Oracle and AI Singapore, which brings together all Singapore-based research institutions and the ecosystem of AI start-ups and companies, are also using the company’s models.
Yogatama said ever since the first models in the Reka family (Flash and Edge) launched, the company has seen strong interest from enterprises and has a strong customer pipeline in place. He added the company will share more about its partnerships in the coming weeks.
Yogatama said that the first year of the company was all about bringing the models to the market. Now, as the next step, it wants to build on this work while accelerating the business functions at the same time. On the product side, the company is training Core to further improve its performance and also working on the next version at the same time.
However, with all the work being done, Yogatama did note that the company has no plans of open-sourcing the technology. He said he continues to be a strong supporter of open-source but it’s about finding the right “balance between what to share and what not to share” to continue growing as a business.


