

Before data scientists can uncover correlations, anomalies and other signals hidden in large volumes of data, they must perform tedious and time-consuming work: getting the data ready for analysis.
The process, known as data transformation, is not generally thought of as a sexy task. But startup Trifacta has come up with software that speeds up the process and makes it more interactive and less code-intensive. Such improvements could minimize the sheer ugliness of data transformation and free up data scientists to do far more important work.
[aditude-amp id="flyingcarpet" targeting='{"env":"staging","page_type":"article","post_id":890641,"post_type":"story","post_chan":"none","tags":null,"ai":false,"category":"none","all_categories":"big-data,","session":"A"}']Today Trifacta finally launched its software, more than a year since it came out of stealth and a couple of months since it announced $12 million in new venture funding.
Lockheed Martin and Accretive Health are using the technology across large-scale data sets, Trifacta chief executive Joseph Hellerstein told VentureBeat in an interview. If many more companies start using the software and discover how simple data transformation can be, Trifacta — or at least its approach — could one day end up being credited for lowering the barrier to entry for big data projects.
AI Weekly
The must-read newsletter for AI and Big Data industry written by Khari Johnson, Kyle Wiggers, and Seth Colaner.
Included with VentureBeat Insider and VentureBeat VIP memberships.
“The basic idea is that users should be able to always visually interact with data, and always be in sort of a high-level visual experience,” Hellerstein said.
Trifacta’s software takes a small bite of a large file and displays the sample in familiar spreadsheet format to users. From there, a user can click around with a mouse and highlight the important bits of text within a cell and then direct the software to pull that type of data into a new column right on screen. Each column gets a basic visualization of the data, like a histogram, to put data in some context. Users can then trim down the data set to fit a more specific focus.
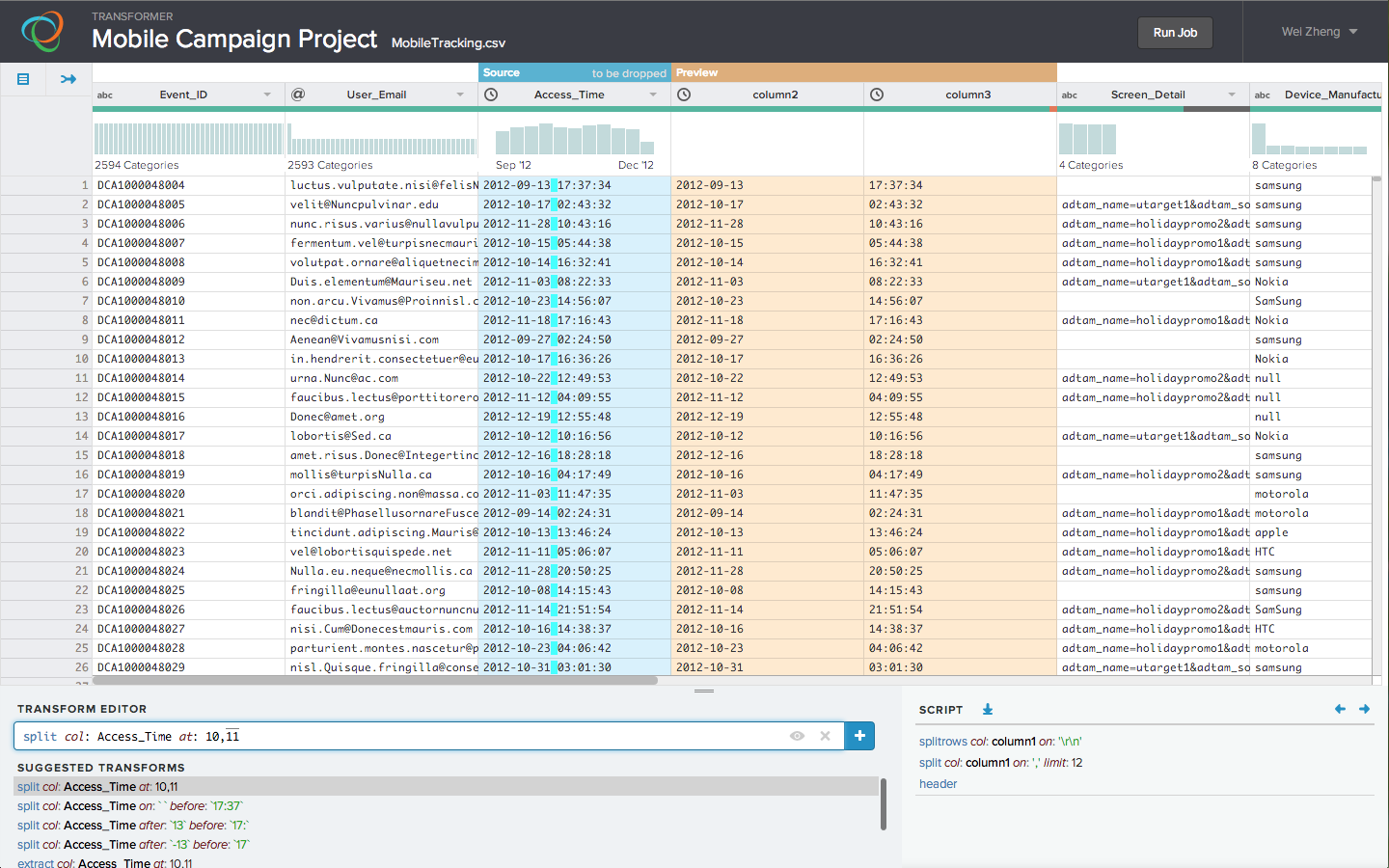
The software takes guesses at what users want to do with the sample data set, sort of like the auto-complete feature in Google’s search bar. Users can preview the results of the available actions Trifacta suggests. Once users select the changes to be made, they’re added to a sort of to-do list for the entire data set.
Except users never have to deal with writing the complicated lines of code that will actually do the transformation inside the highly scalable open-source Hadoop file system. The software automatically generates the scripts that Hadoop can understand.
That ease of operation adds to the appeal of Trifacta’s software. Simple point-and-click data transformation without coding can give greater data analytics capabilities to people who might otherwise stay far away from large data sets. And that means the impact of this software can span beyond card-carrying data scientists.
[aditude-amp id="medium1" targeting='{"env":"staging","page_type":"article","post_id":890641,"post_type":"story","post_chan":"none","tags":null,"ai":false,"category":"none","all_categories":"big-data,","session":"A"}']
VentureBeat's mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Learn More