

Though the economy is growing, we’re still suffering in the aftermath of the Great Recession, and many ambitious workers are eager to get training in skills with the highest pay. To see which skills were in the highest demand, LinkedIn’s engineers tapped their massive dataset of job promotions and transfers. They discovered that one skill set above all had the highest correlation of future success: “statistical analysis and data mining.” In other words, data scientists have the hottest skills on the market.
Indeed, data scientists are so sought after that the White House has stepped in to encourage universities and tech education startups to upgrade their existing courses to satisfy the unmet demand.
[aditude-amp id="flyingcarpet" targeting='{"env":"staging","page_type":"article","post_id":1627709,"post_type":"story","post_chan":"none","tags":null,"ai":false,"category":"none","all_categories":"big-data,business,","session":"D"}']Here are a few questions to see whether you have some of the basic knowledge required to be a data scientist. The questions are pulled from statistics courses, tech company interview questions, and a bit of programming basics. Two of the 4 have a right/wrong answer. We’ll show you those answers at the end.
QUIZ
1. Suppose you went cave diving in Mexico and have contracted a rare disease. You go to the doctor, and he tells you that the test for such a disease is correct 99 percent of the time, but since it is so rare, it only occurs randomly in the population 1 out of 10,000 times.
AI Weekly
The must-read newsletter for AI and Big Data industry written by Khari Johnson, Kyle Wiggers, and Seth Colaner.
Included with VentureBeat Insider and VentureBeat VIP memberships.
Your tests come back positive. What are the chances you have the disease?
A) 99%
B) 90%
C) 10%
D) 1%
2. Can you evaluate this code?
Answer <- "Data science is #"
fact <- sd(-1:1)
lapply(Answer, paste, fact)
[aditude-amp id="medium1" targeting='{"env":"staging","page_type":"article","post_id":1627709,"post_type":"story","post_chan":"none","tags":null,"ai":false,"category":"none","all_categories":"big-data,business,","session":"D"}']
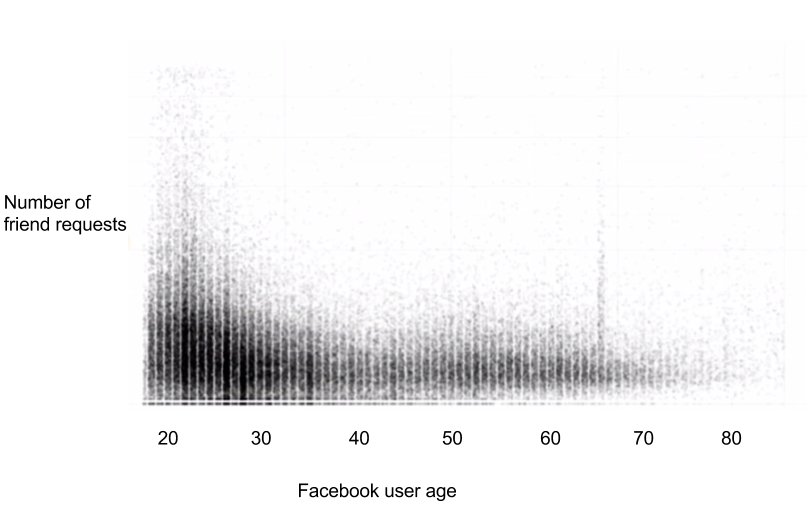
3. Here’s a faux graph of every Facebook user’s age and friend count. If you had this data, could you redraw the graph so that only the average friend count from each age was displayed as a line graph?
4. You have results from an A/B experiment. You applied some treatment X and want to measure the conversion rate Y. How do you control for confounding variable Z? Compute P(Y|X) after adjusting for Z.
Answers:
[aditude-amp id="medium2" targeting='{"env":"staging","page_type":"article","post_id":1627709,"post_type":"story","post_chan":"none","tags":null,"ai":false,"category":"none","all_categories":"big-data,business,","session":"D"}']
1) It’s closest to 1%. The key to this question, which plagues the field of breast cancer research, is to take into account the number of false positives. Because it’s so rare, there will be more false alarms than correct diagnoses. This question comes courtesy of education startup, Udacity.
2) The code is equivalent to: “Data science is #1”. These are 3 lines in the popular programming language, R.
3) It’s not a yes or no answer, but the process would involve grouping every row in the data by age and computing the mean, then regraphing. The graph was taken from one of the advanced lessons in the Udacity data science course.
4) According to wage data startup, Glassdoor, this was an actual interview question for a Facebook data scientist position. The most popular answer on the forum was “Sum P(Y| X,Z)*P(Z)”. To translate the question into English, a “confounding variable” is just something that makes it seem like y causes x, when really it doesn’t.
[aditude-amp id="medium3" targeting='{"env":"staging","page_type":"article","post_id":1627709,"post_type":"story","post_chan":"none","tags":null,"ai":false,"category":"none","all_categories":"big-data,business,","session":"D"}']
So, for instance, if there is a correlation between murder rate and ice cream sales, it’s not that selling ice cream inspires violent rampage. It could just be that warmer weather causes both. To answer this question, an interviewee could also say that they would “control” for the Z variable in the common statistical procedure known as a “regression.” I don’t think a data scientist necessarily has to know how to do math proofs.
Long before I become a journalist, I was lucky enough to be trained in statistical analysis. But many of the techniques I learned only a few years ago are out of date as new datasets and software have come on the market. I’ve been trying out a number of stat courses from online providers, including Udacity and Coursera.
I’m a fan of both of their online data science courses so far, and I think they’re very much comparable (and in some ways better) to a university degree. After finishing the courses, a graduate would have the skills to do basic data science. The going rate for a data science track from an online education provider is about $500 and takes about six weeks. For something more intensive, the 12-week, in-person data science “boot camp” from Galvanize’s Zipfian Academy costs $16,000.
Given the amount of money to be made, it’s not a bad investment to do all of the available options.
[aditude-amp id="medium4" targeting='{"env":"staging","page_type":"article","post_id":1627709,"post_type":"story","post_chan":"none","tags":null,"ai":false,"category":"none","all_categories":"big-data,business,","session":"D"}']
VentureBeat's mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Learn More