

This sponsored post has been produced by Andy Palmer, the chief executive of Tamr.
Three years ago, my partner Mike Stonebraker was working on a research project at MIT to test the boundaries of data integration and curation.
[aditude-amp id="flyingcarpet" targeting='{"env":"staging","page_type":"article","post_id":1477396,"post_type":"sponsored","post_chan":"sponsored","tags":null,"ai":false,"category":"none","all_categories":"big-data,business,enterprise,","session":"B"}']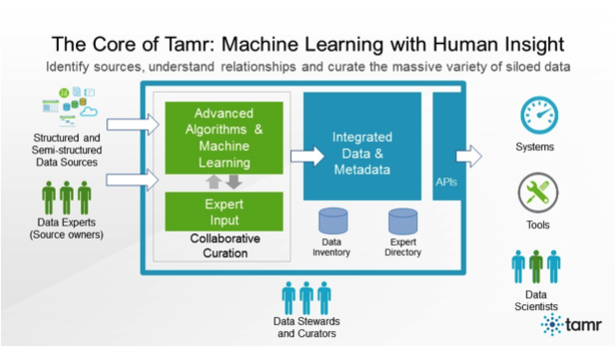
Mike and his fellow researchers wanted to see if it was possible to connect thousands or even tens of thousands of sources together. The research team was working with a number of companies to test the real-world application of their research. Around this time, I was hanging out at the Novartis Institutes for Biomedical Research (NIBR), focusing on data integration and software engineering.
Turns out we had a project at NIBR that involved the integration of 15K sources — good commercial context for Mike’s academic effort. In a fantastic collaboration between the researchers at MIT and the data curation team at NIBR, we found that the designs of the academic system were capable of handling a lot of sources, but that we also needed to include a collaborative/expert sourcing capability to tune the recommendations generated by the machine learning algorithms in the initial system.
We described the results of the academic work in a paper published in early 2013 called “Data Tamer.”
Mike and I had also seen a similar pattern when we were at Vertica. Working with our customers at Vertica, we’d go through the process of identifying all the data sources to feed into a warehouse. We’d implement with a bunch of top-down extract-transform-load (ETL) processes, get the queries running, and then the users would have a new source that they wanted to add or an attribute from an existing source that they had forgotten.
At that point, they had two choices:
- Ignore the new data, even though they knew it was useful, or
- Start over, reengineering the ETL from the top down … again.
More often than not, the team would decide to ignore the new data, which seemed like a huge missed opportunity. In the back of our minds we were always thinking, “What about the other sources that have been left out or might come along in the next few years?”
We also started to see many distributed instances of MongoDB and CouchDB — these great new JSON data sources that needed to be integrated — but there were so many and they were so unstructured that it was difficult for people to plug them into existing integration projects.
[aditude-amp id="medium1" targeting='{"env":"staging","page_type":"article","post_id":1477396,"post_type":"sponsored","post_chan":"sponsored","tags":null,"ai":false,"category":"none","all_categories":"big-data,business,enterprise,","session":"B"}']
After seeing this scenario play out dozens of times, Mike and I came to believe that the ability to connect and curate many thousands of new sources in an automated way was a core missing capability in large enterprise data infrastructure.
Now we believe that the time has come to embrace the reality of extreme data variety across the entire enterprise. As it turns out, the thoughtful connection of machine learning with expert human guidance is the real trick to solving this problem of data variety. Making the interaction between experts and the machine both simple and scaleable has been a fantastic challenge and our most significant achievement over the past few years.
Tamr’s “bottom-up” approach employs advanced algorithms and machine learning to automatically inventory and connect this huge variety of diverse data sources. Our system embraces the inherent ambiguity of integrating a broad variety of data from many thousands of sources. Every connection in our system — between sources, attributes, records, entities, and experts — has a confidence level that can change over time, improving with the active input from experts as well as the learning gained by continuously integrating new sources and changes to existing sources.
This probabilistic, bottom-up approach complements the traditional deterministic, top-down approach of traditional enterprise data modeling.
[aditude-amp id="medium2" targeting='{"env":"staging","page_type":"article","post_id":1477396,"post_type":"sponsored","post_chan":"sponsored","tags":null,"ai":false,"category":"none","all_categories":"big-data,business,enterprise,","session":"B"}']
Ultimately, Tamr’s “machine-driven, human-guided” solution scales to include teams in multiple departments, connecting all internal and external sources within the enterprise, mapping sources, attributes, records, and entities. The resulting integrated set of data and metadata is accessible via RESTful APIs to any data scientist, analyst or system.
As Mike and I well know, there is tremendous investment and value in MDM and ETL solutions that companies should leverage and complement with a bottom-up, probabilistic system like Tamr. Complementing and adding value to those investments was a major design point of the Tamr product.
Which brings us full circle: back into MIT and the research we began four years ago. While Mike and I didn’t have a new company as a “to-do” item when we started, after three years of development driven by world-class research, real-world customers and top-tier engineering, we’re humbled to begin opening up the Tamr system to new customers and partners.
Sponsored posts are content that has been produced by a company that is either paying for the post or has a business relationship with VentureBeat, and they’re always clearly marked. The content of news stories produced by our editorial team is never influenced by advertisers or sponsors in any way. For more information, contact sales@venturebeat.com.