![]() More than a year of secrecy spawned rumors about Radar Networks. The most popular: It’s a “Google killer.”
More than a year of secrecy spawned rumors about Radar Networks. The most popular: It’s a “Google killer.”
Tomorrow morning, San Francisco’s Radar will surprise a few people by launching Twine, a tool for collecting and organizing information that’s very different from Google. But it’s potentially just as ambitious.
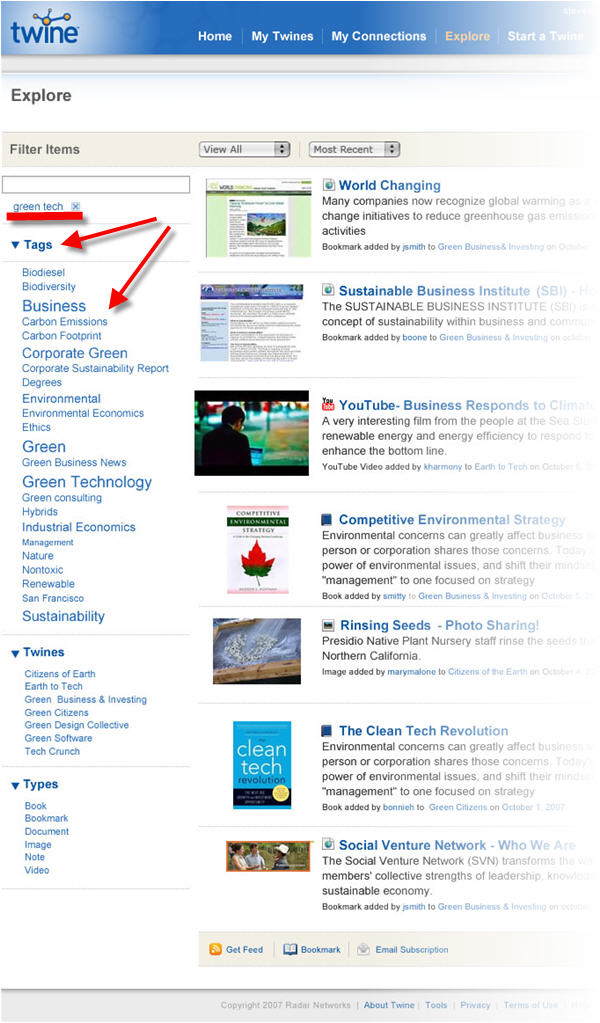
An example of how Twine works: A user uploads a text document to their Twine account. Twine then parses the document to find the words with meaning — names, places, concepts and so forth. Those terms become tags, which the person can use to access related information.
Twine’s underlying technology gives the computer a measure of intelligence. Using tags, a computer can distinguish between, say, a reference to the kind of bird that flies and the kind that flips people off. Once it has, it can give users a wealth of other information, drawn from their own accumulated knowledge base, other users and the outside internet. Where Google crawls the entire web and ultimately pollutes your search results with different kinds of “birds,” Radar picks from a smaller universe of sources and tries to automatically discard the ones you don’t want.
Let’s dumb this down to a very concrete example. In Twine, I might be identified as “Chris Morrison,” and then labeled with the markers “writer,” “venturebeat,” “male,” “technology,” “charming” and “good-looking” (all true, of course). Twine would set me apart from the many other Chris Morrisons running around.
That could help a headhunter narrow their focus, a marketer collect all the information about a particular product, or a group of analysts to aggregate information on a subject. The “documents” gathered will include, among many others, text, PDFs, or even videos on YouTube (Twine simply draws on pre-existing tags and descriptions of visual media to do its own tagging work).
The information that helps Twine make decisions on its own about what content to collect for you comes both from a users’ accumulated information as well as their actions, which means that, as the user pulls more info into the account on their own, Twine will begin to work cooperatively, providing more content where it’s needed and even assisting groups or teams of people with collaborative research and knowledge-building.
Young companies with a limited ability to do similar selection tricks — for instance, Jiglu, which we posted about a few days ago — are increasingly common, and tend to obscure the potential of companies that truly have a chance of becoming market leaders. That’s too bad, because there’s no question that intelligent computer handling of data — a first step toward artificial intelligence — will be an important part of the internet in coming years.
 Helping Radar is the breadth of its underlying technology and the strong scientific and engineering team, now 30 strong, that has been working on the platform for years. It is founded by Nova Spivack (left), an entrepreneur who worked on artificial intelligence with futurist Ray Kurzweil. He later co-founded the early internet company EarthWeb, which went public in 1999, and helped other large companies get online.
Helping Radar is the breadth of its underlying technology and the strong scientific and engineering team, now 30 strong, that has been working on the platform for years. It is founded by Nova Spivack (left), an entrepreneur who worked on artificial intelligence with futurist Ray Kurzweil. He later co-founded the early internet company EarthWeb, which went public in 1999, and helped other large companies get online.
So how does Twine plan to make money? If it’s busy reading the minds of its users, there should be some significant advertising mojo possible. Twine also plans a paid version with no advertising.
For now, though, the company is venture backed. As we reported last year, the company raised $5 million for Paul Allen’s Vulcan Capital, Leapfrog Ventures and angel investors. We’re hearing the company is looking to raise about $15-20 million for its next round.
Radar does, however, have competitors. The winning bet will boil down to which company will be able to throw enough scientific brilliance at the difficult problem of teaching computers to understand human information. The winner will likely dominate, as Google does with search.
To explain the differences between these competing startups, it’s easiest to separate them by the particular types of technology they utilize.
Broadly speaking, those technologies fall into three categories.
1) The first is statistical analysis, where Google reigns supreme. Terms are examined for their frequency, placement and outside links to determine their apparent relevancy, and then ranked. Google’s algorithms have gotten better over the years, and it has incrementally added on other technologies and services.
2) Natural language search is the second category. Teaching computers to understand human language is a complex process which involves breaking sentences down to their component parts — nouns, verbs, adjectives and so forth — which can then take on symbolic meaning for computers. Powerset (previous coverage), which is dribbling out its technology in stages, is a prime example of this approach.
3) The third, semantic search, is much-hyped, but little understood. Simply put, people attach markers to human-generated content, whether a paragraph of text or a picture, to outright tell computers in a special machine language what’s meaningful (we mentioned the “Chris Morrison” = “charming” example, above). If applied to the entire internet, the result could be thought of as a giant, interrelated Wikipedia. Metaweb, which recently launched Freebase, is attempting to create just that. It should be noted that Powerset, of category #2 above, has partnered with Metaweb, thus placing Powerset in this third category as well in some ways.
For the most part, each company is betting on its own core technology to win the race. Radar, however, works with all three. That combination, it hopes, will take the day. It is similar in its ambitions to another secretive startup, Franz Inc, which VentureBeat plans to write about soon.
To be fair, there’s also a fourth, less glamorous approach which relies almost entirely on humans. ChaCha and a forthcoming (much delayed) startup from Wikipedia founder Jimmy Wales are two examples.
First, though, the viability of any technology must be proven. What matters is how well Twine can perform at helping humans organize the avalanche of information that is modern life. So while there are other features we could mention, from organizing content through an innovative “bookmarklet” to finding related content through a “social graph” of similar users, it’s more useful to give our reaction to Twine.
Having sat through a limited demo by Radar founder Nova Spivack, we can say we’re looking forward to kicking the tires of Twine more extensively. The interface is simple, yet powerful. While the use of tagging resembles tag-lists that have been around for years, the Twine application is more powerful. See the example of a search for “clean-tech” below. See the various tags that are related to it.
Caveat: The site is still in development. A wealth of other features would be helpful to have, from a more extensive array of choices for communicating with other users (Spivack does say that instant messaging is coming) to adding more possibilities for linking information.
However, the Twine team won’t have to do the work alone. Sometime after the current beta launch, which will be limited to a few thousand people, Twine plans to open up several APIs to allow outside developers to build on the platform.
For now, the site is geared toward people who use the internet heavily — primarily “knowledge professionals,” like the marketers and analysts mentioned above. Students, “prosumers” (people with a strong interest in a particular thing) and companies will also likely find uses for Twine.
For more discussion of Radar’s idea of the future — including what could go wrong — we’ll post a Q&A with Nova Spivack on Saturday.
Also worth reading: The early Business 2.0 story about Radar.
VentureBeat's mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Learn More
