
This sponsored post is produced by Nati Shalom, CTO and Founder at GigaSpaces.
The big data movement was pretty much driven by the demand for scale in velocity, volume, and variety of data. Those three vectors led to the emergence of a new generation of distributed data management platforms such as Hadoop for batch processing and NoSQL databases for interactive data access. Both were inspired by their respective predecessors Google (Hadoop, BigTable) and Amazon (Dynamo DB).
As we move to fast data, there’s more emphasis on processing big data at speed. Getting speed without compromising on scale pushes the limits in the way most of the existing big data solutions work and drives new models and technologies for breaking the current speed boundaries. New advancements on the hardware infrastructure with new flash drives offer great potential for breaking the current speed limit which is bounded mostly by the performance of hard drive devices.
Why using existing RDBMS, NoSQL on top of flash drive is not enough
Many of the existing databases — including more modern solutions such NoSQL and NewSQL — were designed to utilize the standard hard drive devices (HDD). These databases were designed with the assumption that disk access is slow and therefore they use many algorithms such as Bloom filters to save access to disk in case the data doesn’t exist. Another common algorithm is to use asynchronous write to commit-log. A good insight into all the optimizations that are often involved in a single write process on NoSQL databases is provided through the Cassandra Architecture. Let’s have a look at what that entails below:

The Cassandra write path
What happens when disk speed is no longer the bottleneck?
When the speed of disk is no longer the bottleneck, as in the case of flash devices, then a lot of the optimization turns into overhead. In other words, with flash devices it will be faster and simpler to access the flash device directly for every write or read operation.
Flash is not just a fast disk
Most of the existing use cases use flash devices as faster disk. Using flash as a fast disk was a short path to bypass the disk performance overhead without the need to change much of the software and applications. Having said that, this approach inherits many unnecessary disk driver overhead. So to exploit the full speed potential of flash devices, it would be best to access the flash devices directly from the application and treat flash devices as a key/value store rather than a disk drive.
Why can’t we simply optimize the existing databases?
When we reach a point in which we need to change much of the existing assumptions and architecture of the existing databases to take advantage of new technology and devices such as flash, that’s a clear sign that local optimization isn’t going to cut it. This calls for new disruption.
The next big thing in big data
Given the background above, I believe that in the same way that demand for big data led to the birth of the current generation of data-management systems, the drive for fast data will also lead to new kinds of data management systems. Unlike the current set of databases, I believe that the next generation databases will be written natively to flash and will use direct access to flash rather than the regular disk-based access. In addition to that, those databases will include high performance event streaming capabilities as part of their core API to allow processing of the data as it comes in, and thus allowing real-time data processing.
Fast data in the cloud
Many of the existing databases weren’t designed to run in cloud as first-class citizens and quite often require fairly complex setup to run well in a cloud environment.
As cloud infrastructure matures, we now have more options to run big data workload on the cloud. The next generation databases need to be designed to run as a service from the get-go.
To avoid the latency that is often associated with such a setup, the next generation databases will need to run as close as possible to the application. Assuming that many of the applications will run in one cloud or another, it means that those databases will need to have built-in support for different cloud environments. In addition, they will need to leverage dynamic code shipping to pass code with the data, and in this way allow complex processing with minimum network hops.
In-memory databases and data grid are the closest candidates to drive next-gen flash databases
RAM and flash-based devices have much more in common than flash and hard drive. In both RAM and flash, access time is fairly low and wasn’t really the bottleneck; in-memory databases use direct access to the RAM device through key value interface to store and index data.
Those factors makes in-memory based databases more likely to fit into the next generation flash databases.
The combination of in-memory databases and data grid on top of flash devices also allows the system to overcome some of the key capacity and cost per GB limitations of an in-memory based solution. The integration of the two will allow an increase in the capacity per single node to the limit of the underlying flash device rather than to the limit of the size of RAM.
The overall architecture of the integrated solution looks as follows (Source: Gartner):
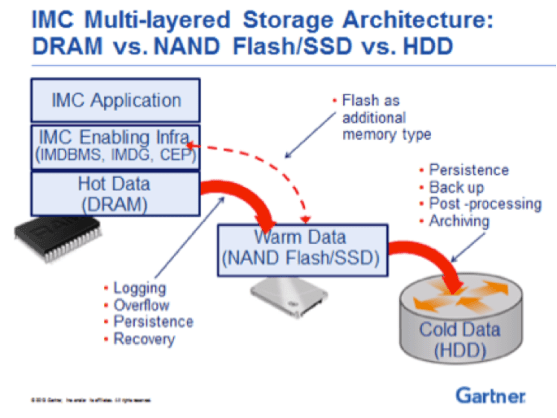
As can be seen in the diagram above, the IMC (in-memory computing) layer acts as the front end to the flash device and handles the transactional data access and stream processing, while the flash device is used as an extension of the RAM device from the application perspective.
There are basically two modes of integration between the RAM and flash device.
LRU Mode – In this mode, we use the RAM as a caching layer to the flash device. The RAM device holds the “Hot,” i.e. the most recently used, and the flash device holds the entire set.
Pros: Optimized for maximum capacity.
Cons: Limited query to simple key/value access
Fast Index Mode – In this mode, all the indices in RAM and the data in flash holds the entire set.
Pros: Supports complex querying, including range queries and aggregated functions.
Cons: Capacity is limited to the size of indexes that can be held in RAM.
In both cases, the access to flash is done directly using key/value interface and not through disk drive interface. As both RAM and flash drives are fairly fast, it is simpler to write data to the flash drive synchronously and in this way avoid potential complexity due to inconsistency.
It is also quite common to sync the data from the IMC and flash devices into an external data store that runs on a traditional hard drive. This process is done asynchronously and in batches to minimize the performance overhead.
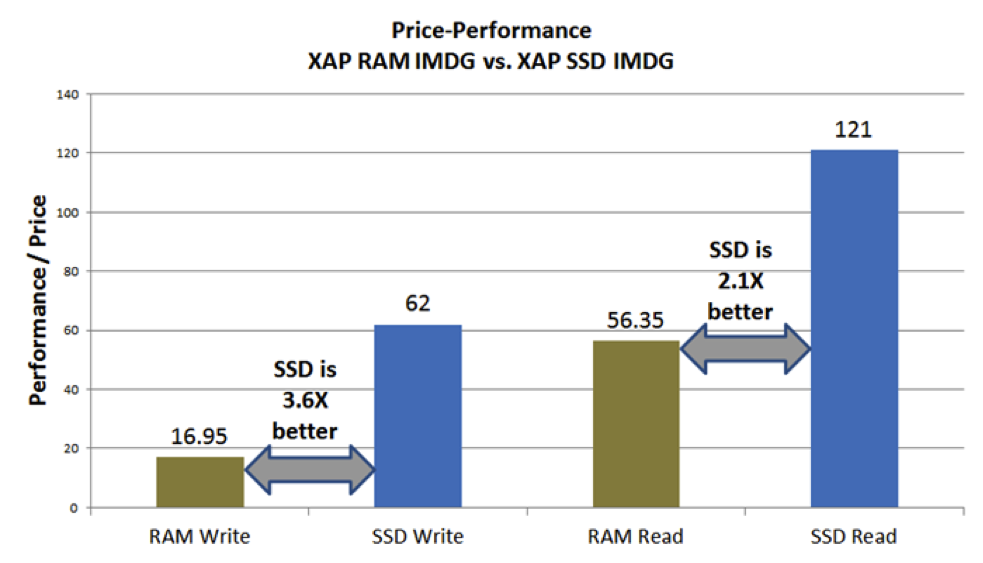
Direct flash access in real numbers
To put some real numbers behind these statements, I wanted to refer to one of the recent benchmarks that was done using an in-memory data grid based on GigaSpaces XAP and direct flash access using a key/value software API that allows direct access to various flash devices. The benchmark was conducted on several devices as well as on private and public cloud-based services on AWS. The benchmark shows a ten times increase in managed data without compromising on performance.
For full details of the benchmark, see the following white paper:
XAP MemoryXtend -Massive Application Storage Capacity for Real-Time Applications
.
Sponsored posts are content that has been produced by a company that is either paying for the post or has a business relationship with VentureBeat, and they’re always clearly marked. The content of news stories produced by our editorial team is never influenced by advertisers or sponsors in any way. For more information, contact sales@venturebeat.com.
