
This sponsored post is produced by MaxPlay.
Virtual Reality is ushering in an era of amazing new experiences, but it also introduces a variety of new challenges that require innovative solutions. One such challenge is the “power hungry” nature of Virtual Reality applications.
VR pushes the envelope in graphics and simulation, so much so that the hardware requirements for good VR experiences have recently become a hot topic. These steep requirements put a ton of pressure on the software behind the VR experiences to fully utilize the available hardware, including making better use of multicore CPUs.
The rise of multicore
In the ongoing race to make computers faster, transistor counts multiply and CPU clock speeds have steadily increased. Unfortunately, as more transistors are added and clock speeds increase, the processors need more and more energy to operate, therefore generating more heat. Excess heat damages the CPU components and you may have noticed that when you’re playing some games on your phone, it can become uncomfortably warm. CPU manufacturers must balance clock speed and heat in order to stay within a safe range of heat for the device, which is also known as the thermal envelope.
The most significant trend to combat this problem is to put multiple CPU execution cores on one physical chip running at a lower clock speed. A CPU with two cores can execute tasks basically as fast as one CPU running twice the speed. However, the dual core CPU consumes less energy and therefore stays cooler.
Today, it’s almost impossible to buy a CPU with only one core. The iPhone 6 has a processor with 2 physical cores. High-end Android phones come with as many as 8 cores. Major PC manufacturers are now producing chips with 8 cores for the consumer market. Even the PlayStation 4 has an 8 core processor, although until recently, developers only had access to 6 of the 8.
However, to take full advantage of multiple cores, an effective multithreading software architecture is a requirement.
Programming for multicore
As the saying goes, “there’s no such thing as a free lunch” — and multithreading a program or engine to utilize multiple CPUs requires careful thought. Public enemy number one is data contention. Multiple CPU execution paths need access to the same data.
Here’s a relatively simple example. Let’s say that one CPU writes a value into memory, literally at the same time another CPU is trying to read that exact same value. The second CPU may read partially-written data, which is therefore useless data. This is called a race condition which can crash a program or lead to unexpected results.
To protect data from simultaneous CPU access, programmers employ synchronization objects. While this synchronization process does work, it can result in CPUs waiting for synchronization, which leads to uneven performance and wasted time. Architectural designs that minimize the number of synchronizations required are definitely the best. This is what makes fully utilizing a multi-core processor’s full potential difficult. If programmers don’t design and implement applications correctly to take advantage of multiple cores they may in fact execute slower.
Performance in a game engine is all about gathering input, simulating the world, and rendering. The faster and more evenly you can do that, the better the frame rate and user experience will be. To achieve 90 frames per second requires that you gather input, simulate the world, and render it in 11 thousandths of a second.
For VR, rendering has to be done twice, once for each eye. Eleven thousandths of a second is a really short amount of time, so game developers struggle to keep that 90 FPS frame rate, usually by reducing quality of content until it’s achieved. Of course, reducing the quality of the content may result in a sub-par experience.
In many engines, they have been retrofitted to support multiple cores through a few design modifications. This will improve performance for a few cores, but data contention minimizes potential gains, and furthermore, doesn’t scale well beyond just a few CPU cores
Retrofitting for multicore
Most retrofitting in popular games is achieved with various forms of functional multithreading.
The first thing that is usually added is separating the renderer into a separate thread. Next, areas are identified that more easily lend themselves to parallelization such as physics and AI.
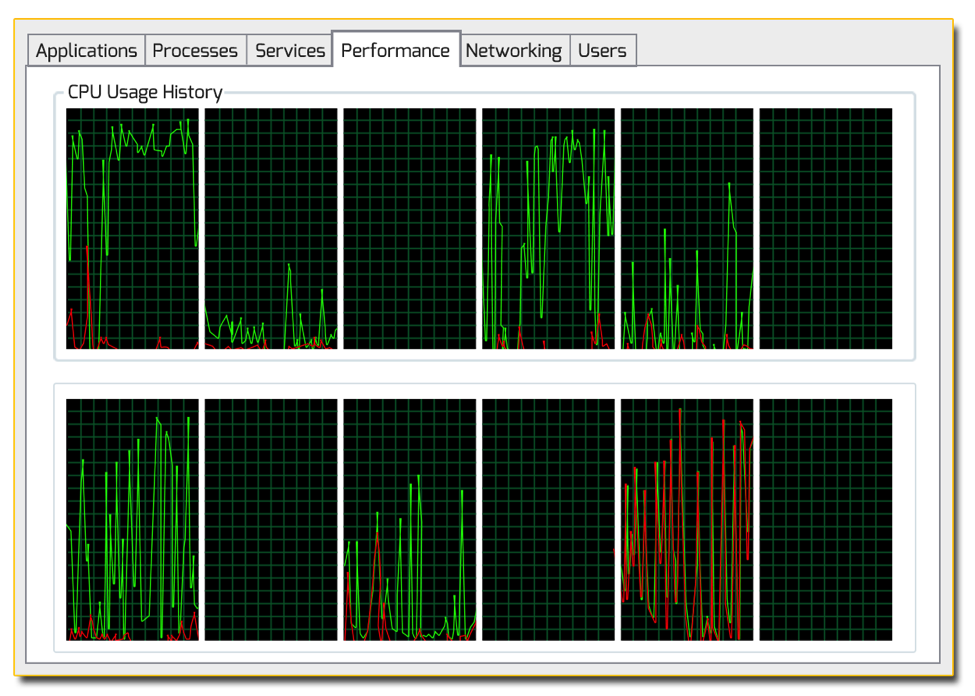
Instead of looping over all of the physics and AI objects in a linear fashion, the work is distributed across multiple threads which run on multiple CPU cores. When that work is done, the program returns to linear execution. More advanced systems use a job model that allows the threads to pick up work if they are available. In practice this type of multithreading can realize some reasonable gains, but there will be large amounts of CPU processing time in the frame that is wasted waiting for synchronization or with no work for one or more of the CPUs. Hand tuning may work for a particular product, but it doesn’t load balance itself well automatically. The result is uneven CPU usage. Even the game community at large has recognized that most games built with older game engines won’t show much improvement going beyond four cores.
Uneven CPU usage in today’s popular game engines
Another approach. Design an engine for multicore from the start
When you look at current CPU architecture and future device roadmaps, it’s clear that a new system is required that would be scalable across cores, have predictable load balancing, be extensible, maintain flow control over the simulation across “n” number CPU cores, and most importantly, minimize data contention.
One such architecture is called Multistage Data Parallel Simulation
This simulation is modified to scale across the CPU cores, with one core reserved for rendering. In order to achieve this, the simulation is broken into tasks that can all be discretely processed in any order.
This means that the tasks are sorted into multiple stages, such as a read stage, decision making, and write stage. Additionally you may need a broadcast stage for communication among other objects.
All tasks in a stage of execution are guaranteed to complete before the next stage of execution begins. For each stage of execution, an efficient distribution function is needed for load balancing. As cores finish early they are given more work until the stage is finished.
A Multistage Data Parallel Simulation (with an asynchronous renderer)
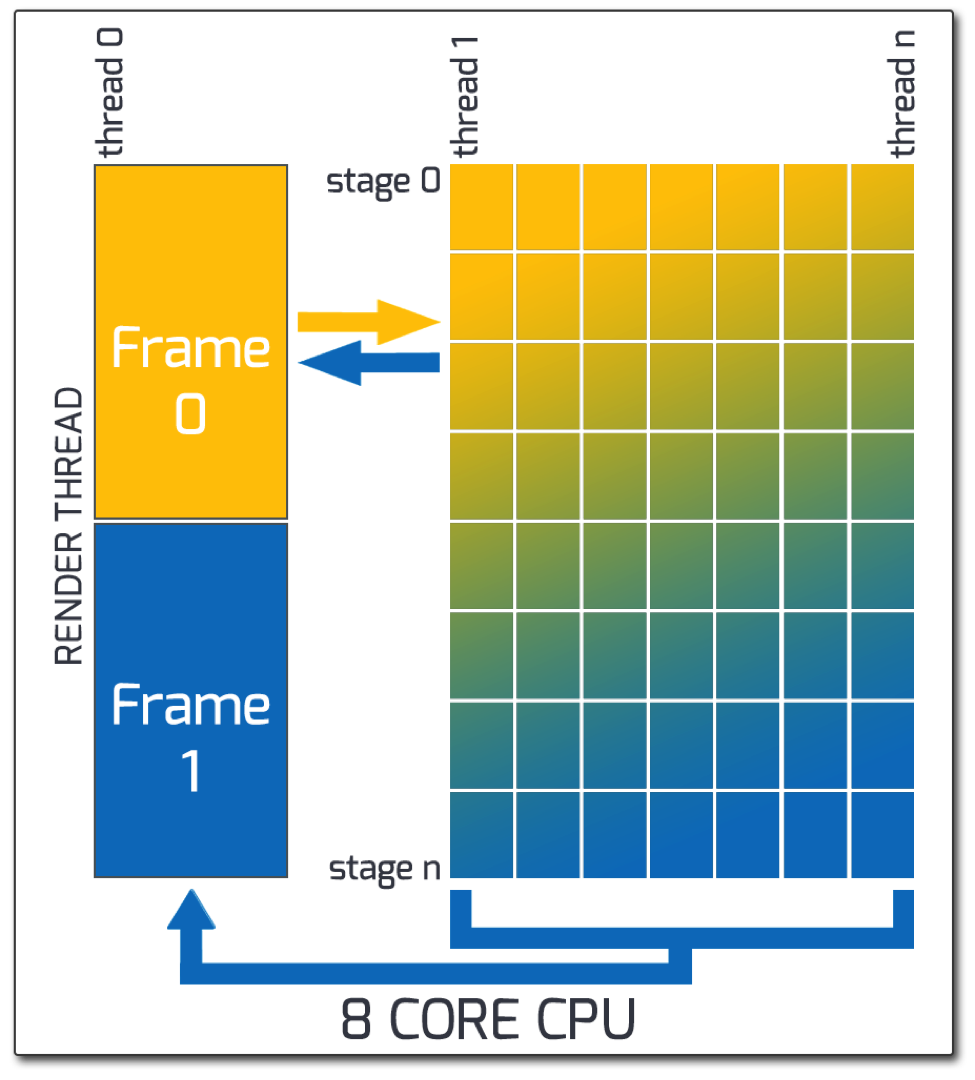
This design should allow a large scale simulation with an asynchronous renderer. To illustrate the potential performance gains, we’ve provided some data points from tests using the MaxPlay runtime engine which uses a similar architecture.
More efficient CPU utilization resulting from Multistage Data Parallel Simulation
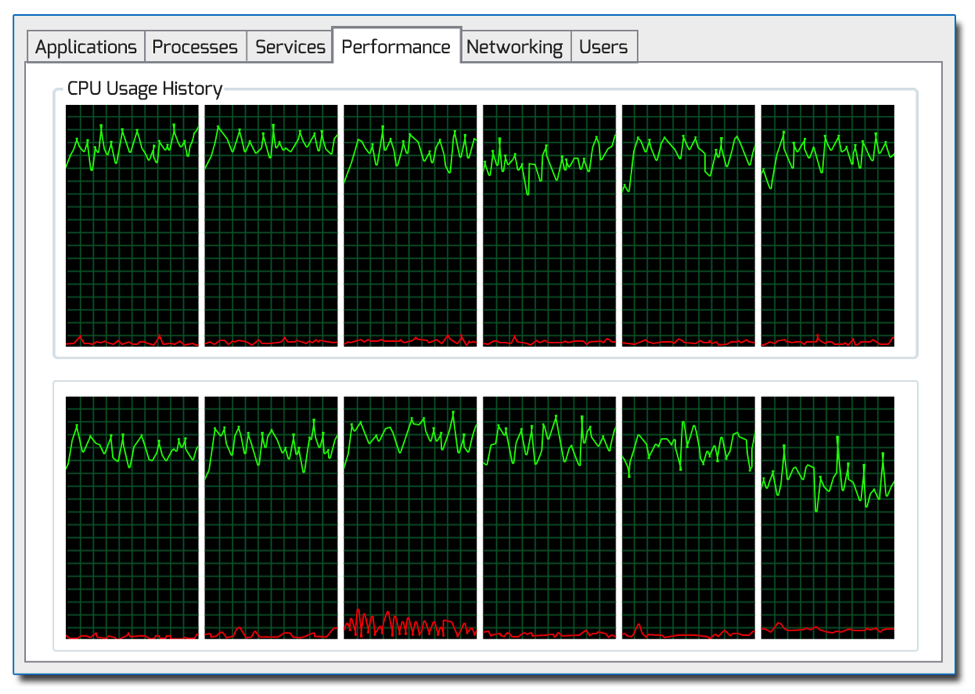
Above you can see the CPU performance of a six core processor (with 6 hyperthreads) running a computationally intensive flocking simulation. Here’s a video showing the performance gains from two to four to six cores for the simulation.
Test results on a variety of hardware platforms indicate significant performance opportunities when compared to traditional functional-multithreading models:
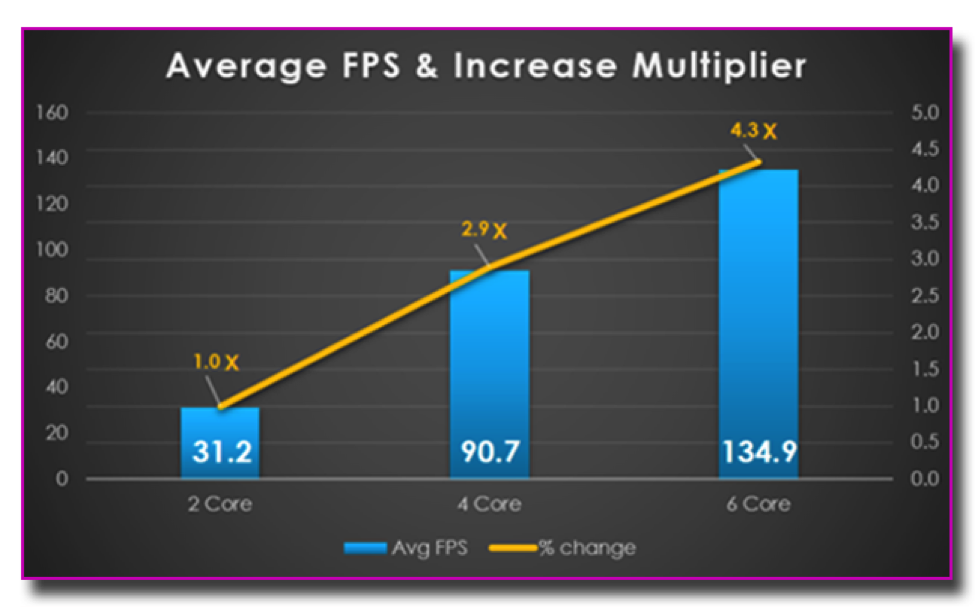
In many cases, we’ve found that employing this technique will yield massive gains in performance, allowing developers to scale more content into their experiences. Indications from hardware manufacturers are that the number of cores will continue to multiply, so it’s important to consider a solution that will scale to 12, 16, and even 24 cores!
For those who wonder about systems with DirectX12 and Vulkan graphic APIs, this architecture is well positioned to send display lists and use returned data to the renderer from any of the stages as needed.
So, if you are looking to tap into the full power of modern multicore processors to enrich your next VR experience, you should consider a solution that employs a Multistage Data Parallel Simulation to maximize your results.
For additional information or questions about multithreading & multicore, please email contact@maxplay.io or visit www.maxplay.io
Matt Shaw is the CTO at MaxPlay, based out of Austin, TX. Matt has led game teams in the games as a service and mobile space for the last 15 years. He most recently served as CTO at BioWare (Star Wars Old Republic, Mass Effect, Dragon Age) and as Head of Technology for EA’s mobile division, POGO. Previous to the acquisition by EA, Mr. Shaw was CTO at Mythic for Warhammer among other award winning online multiplayer and technology platforms.
Sponsored posts are content that has been produced by a company that is either paying for the post or has a business relationship with VentureBeat, and they’re always clearly marked. The content of news stories produced by our editorial team is never influenced by advertisers or sponsors in any way. For more information, contact sales@venturebeat.com.
