
When you play chess or Go, you have perfect information. You know everything about the current state and past history of every piece on the board. When you play poker, or, let’s say, StarCraft, you have imperfect knowledge of both the current state and the past history of the game. Which is closer to life? Imperfect knowledge is, sadly (or blessedly), the truth of human existence for now. Google’s DeepMind is now leading its most powerful artificial intelligence engine deep into our world of ignorance. The result might be a new army of bots that are far more prepared for the “messiness of the real world.”
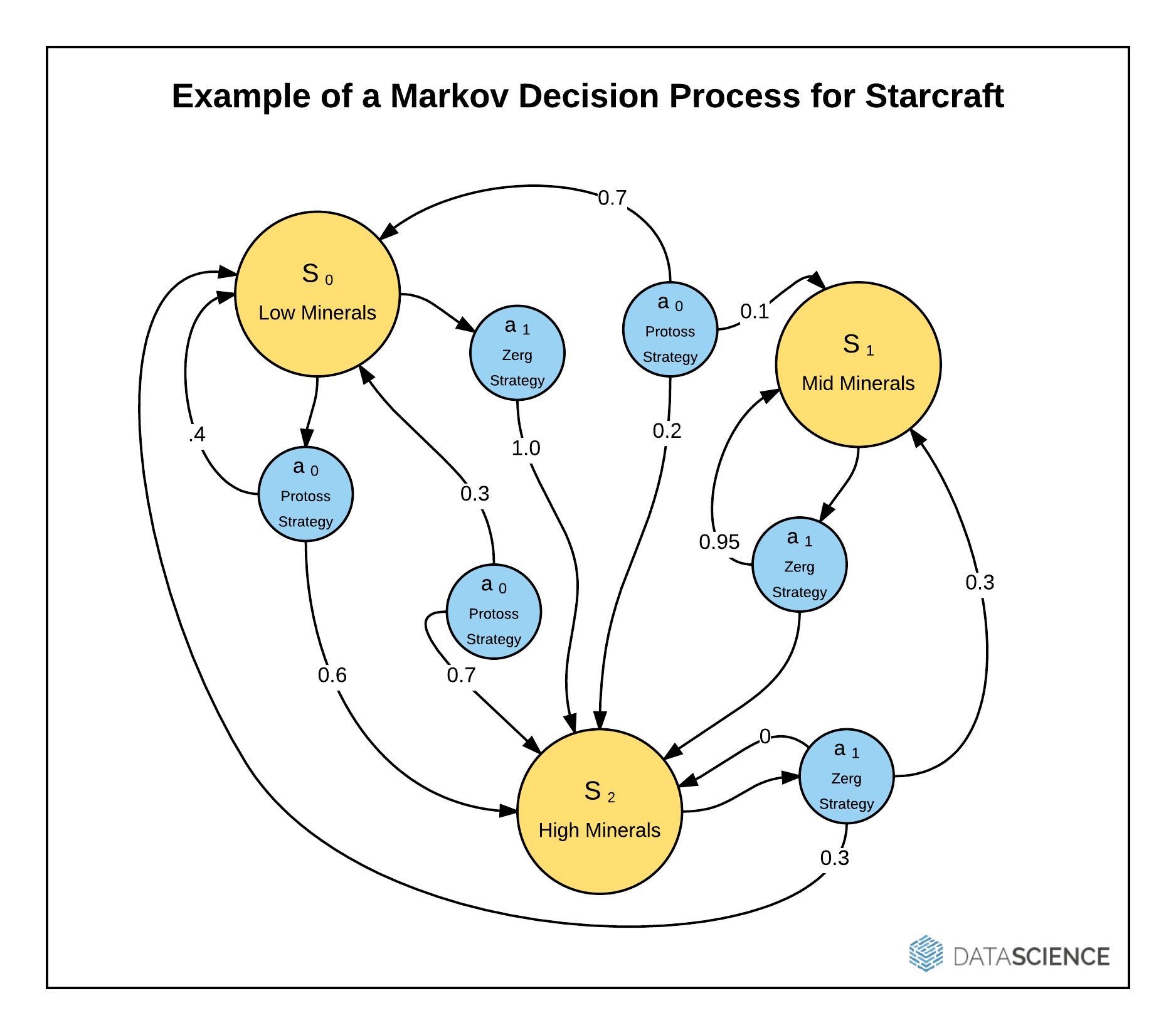
Above: Reinforcement learning is often achieved using Markov decision processes, or MDPs. An MDP takes a particular state (S) and provides probabilities for moving from state to state for a series of actions (a).
Reinforcement learning is a type of machine learning where bots (or artificial intelligences, or behavioral models) are trained to act based on a current state of affairs in a specific environment where the bot has limited knowledge of the world they live in. These bots will develop a (really, really big) handbook for life that gives them some policies to follow when, in the StarCraft II example, you’ve got almost no health, you’re rich in diamonds, and there’s a high probability you’re about to come face to face with Arcturus Mengsk.
Bot: ‘How can I become a real human?’ Data scientist: ‘Slow down!’
If you’re a computer game savant you can maybe do about 400 actions per minute of game play. The top few humans in the world, like Park Sung-joon, have never been clocked at higher than 1000 actions per minute. If you’re a computer bot, you can probably do about 400 trillion actions per minute. However, using this kind of brute force approach to solving a strategy game doesn’t make a bot more human, rather it makes it less human. The limits of humanity can be seen here, in this video demonstration of Starcraft actions per minute by Sung-joon:
Despite the proficiency of professional gamers, they’re still about a trillion times slower than modern computers, so DeepMind is working on measuring the humanity of its bots by slowing down their moves to within the typical boundaries of an average player. For a data scientist, this reduction in speed is very novel, cool, and interesting. Think of this as the slow food movement, but for bots. Research scientist Oriol Vinyals, in his blog post describing the new DeepMind project, explains how mouse clicks, camera angles, available resources, and other decision support has to be methodically performed in real-time by a human. By leveling the playing field so the bot (often referred to as “agents” in the video game sphere) has to move at the same speed as its human comrades and opponents, the agent learns to use sets of actions, often called ‘policies’ in the reinforcement learning sphere, that can be successfully implemented by both bots and humans.
DeepMind and Blizzard aim to ultimately give the bots only the information that we get — pixels on a screen — rather than providing direct Neo-like access to the code that’s generally used to train agents. To get there, they’ve developed a layer of simplified information on top of the screen pixels so that the agent can understand basic visual cues that humans get, such as which type of weaponry is being used, the health of each player, etc. This innovation alone — demonstrated below — is a fantastic step towards creating bots that actually see the (digital) world the same way that humans do.
By constraining bots to only what humans can see and do, data scientists will be able to leverage the massive computing power of deep learning to identify millions of microstrategies that humans have yet to imagine. By studying and releasing these strategies, Deepmind, Google, Blizzard, and the greater research community can learn new approaches that humans can actually take to solve real-world problems that are always multi-dimensional — and that always occur in real time. Furthermore, by restricting artificial intelligence to a human-like time-scale, the bots and agents that are created by the collaboration should be perceived by game players as more human. Presumably, these advances could then be converted to increase the realistic nature of the other bots in our lives.

Above: Humans imitating bots: The real Nova is a StarCraft bot, but the Nova above is a human dressed up like the bot. DeepMind and Blizzard aim to make it easier for bots to imitate humans.
DeepMind’s had some interesting results with agents that beat Atari games, but winning a strategy game like StarCraft II while handcuffed to human constraints is a wholly new level of ambition. In the near future, agents might not just be more intelligent than humans. They might act more human too.
VentureBeat's mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Learn More
