Search Wikia, the highly anticipated search engine by Wikia, the for-profit company of Wikipedia co-founder Jimmy Wales, will launch publicly on Monday. It is currently in private testing mode, and we’ll write more upon launch.
Search Wikia, the highly anticipated search engine by Wikia, the for-profit company of Wikipedia co-founder Jimmy Wales, will launch publicly on Monday. It is currently in private testing mode, and we’ll write more upon launch.
The huge success of Wikipedia in mobilizing humans makes this project particularly notable. It’s a fascinating alternative to Google’s computer-focused approach.
We’ve tested Grub, the service’s way of crawling the Internet’s web sites to collect data. Grub is a “distributed search crawler,” so named because it lets people download a software to do the crawling from their own computers, thereby letting thousands of people contribute to the process. It is intuitive and easy to use. However, large questions remain about the ability of Search Wikia’s approach to scale to the entire Web.
Wikia, the parent company, already has a live service independent of its Search Wikia’s efforts. The current site hosts free wikis — areas of the site open for collaborative editing — for communities in an ad-supported model. The resulting topics covered are usually deeper in detail than the average Wikipedia article. Wikia’s wikis use the same software that powers Wikipedia.
Search Wikia will borrow the ideas and principles that have made Wikipedia so successful–strong community emphasis, transparency, freedom to contribute and free licensing.
Search Wikia’s lofty aspirations of transparency raise some very important questions about the ability of spammers to manipulate search results. All the major search engines guard their ranking algorithms closely in order to prevent such manipulation. It’s clear that Search Wikia will rely on the same kind of community monitoring and self-policing that have made the fully open Wikipedia increasingly popular in spite of the same threats. According to a story by New Scientist, Jeremie Miller, the search project’s technology head honcho, the search service will integrate wiki-like tools to improve search. The ability to vote on search results is an example of such social tools.
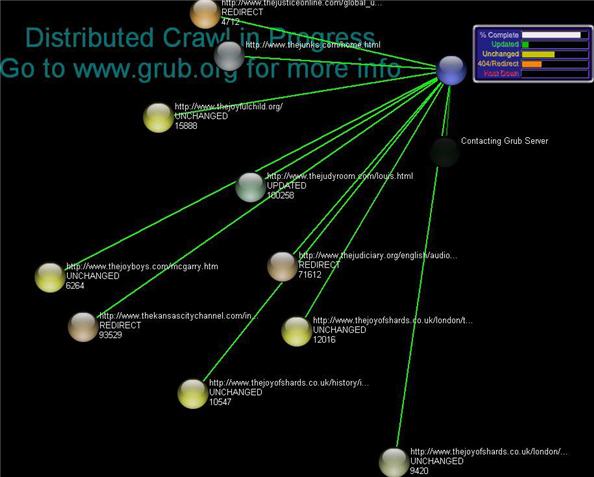
Search Wikia will also rely on a cadre of volunteers to help it crawl the web with the Grub distributed web crawler. The Grub client is a consumer desktop application that harnesses spare CPU cycles on volunteers’ machines and crawls a small portion of the Web. The New Scientist article informs us that the January 7 launch product will have an index of approximately 100 million pages. Given the size and scale of the Web, this is a relatively unimpressive number and quite possibly not big enough to cover one vertical (say, Sports or Health), much less the horizontal universe of queries that any general search engine must be prepared to handle. That being said, widespread usage of Grub by hundreds of thousands of volunteers and an index that actually scales to the Web would be a disruptive development and a new way to think about search.
We tested the Grub crawler client (screenshots below) on a dual core Lenovo ThinkPad T60 laptop running Windows XP. The download and install process was a snap even though the Windows client is running in TEST mode and is expected to be buggy. We ran Grub using a Comcast cable connection for an hour and found that it crawled pages alphabetically by domain name. We also found that the Grub client accessed previously crawled pages to ensure freshness of content and updated the page only when required. We don’t know yet how the Grub system decides which URLs to crawl. It would also be interesting to see published estimates from Search Wikia on how many client installations it takes on average to build a crawl of, say, 30 billion URLs.
We also anticipate that Search Wikia will also rely on the same type of developer community that created world-class open-source projects like Mozilla Firefox and Linux. An April 2007 article in Fast Company says developers have been enthusiastic about being able to tweak complex search algorithms in an open-source environment. It’s easy to imagine a lot of talented developers wanting to try their hand at a problem that’s technically challenging on several fronts (see Anna Patterson’s article: Why Writing Your Own Search Engine Is Hard)
However, this is where the comparisons to Wikipedia become less believable. Wikipedia’s model of allowing anyone to edit pages around particular topics has been successful in part because everyone considers themselves expert enough to contribute cogently on a few topics. The same cannot be said of search technology. It’s unclear whether this community can deliver to the requirements of a web search engine.
Finally, there’s the question of organic traffic to the service. Wikipedia sites constitute the eighth largest set of properties on the Web according to Internet analytics firm ComScore. Wikipedia is a certified Internet brand, but as of December 2006, Google accounted for 50 percent of its incoming traffic, barring certain caveats (see Rick Skrenta’s post for more). It sounds unlikely that Google will send the same volumes of traffic to a competing search service. This also means that Wikia must face the unappetizing task of getting users to switch ingrained search behavior and start their Web surfing at a site other than Google.
Note also that another recent company that started life as a human-powered search engine–Mahalo — seems to be relying on Google SEO for distribution and traffic. As of December 29, 2007, Google has indexed 79,600 pages from the domain Mahalo.com, quite possibly as acknowledgment of the difficulties of driving organic traffic to a competing search engine. Over the next few days, we also plan to investigate questions around the company’s business model, its organizational structure for community developers, the set of social features it will launch with, and when it expects to scale to be able to serve a large portion of queries well.