

REDWOOD CITY, Calif. — In the world of data science, the nerds are just getting around to the merits of Python and Scala over the Java virtual machine (JVM).
“ORLY,” said developers everywhere.
[aditude-amp id="flyingcarpet" targeting='{"env":"staging","page_type":"article","post_id":868639,"post_type":"story","post_chan":"none","tags":null,"ai":false,"category":"none","all_categories":"big-data,dev,","session":"B"}']At the DataBeat/Data Science Summit today, we heard how Ben Lorica, the chief data scientist at O’Reilly Media, and Paco Nathan, the chief scientist at Mesosphere, tackled this (somehow still controversial) topic.
“There’s a lot of folks outside of Twitter using Scala,” said Lorica.
AI Weekly
The must-read newsletter for AI and Big Data industry written by Khari Johnson, Kyle Wiggers, and Seth Colaner.
Included with VentureBeat Insider and VentureBeat VIP memberships.
This might be old news to the dev crowd, but solving big data problems at scale — billion-user, trillions-of-data-points scale — in real time is only a problem computer scientists have had to tackle in recent years.
Take the mobile app explosion. The data set was so massive that analytics company New Relic had to build its own warhorse of a database to handle it.
“There’s room for innovation around scale. Just when you’re drowning in data, there are startups trying to solve that problem,” said Lorica, referencing DataHero, another big data analytics company.
“It’s a needle-in-a-haystack scenario,” said Nathan. “Some of these newer things can get you great returns on your investment.”
This begs the question: How many languages does the data scientist need to know?
“Everyone needs a little JavaScript and other visualization libraries,” said Lorica. “And most people have that one go-to; it might be Python, [or] it might be Scala.”
[aditude-amp id="medium1" targeting='{"env":"staging","page_type":"article","post_id":868639,"post_type":"story","post_chan":"none","tags":null,"ai":false,"category":"none","all_categories":"big-data,dev,","session":"B"}']
Wolfram, Hazy, Spark, IPython Notebook, Vowpal Wabbit, Titan, GraphLab, software-defined networking, and Quid were two other tools commended as being “interesting” by the speakers.
Not so popular were natural language technologies, C++, Mahout, and current technologies for machine-learning data validation.
Here’s the full list of recommended tools. Warning, this is a motherlode; click to see the larger image:
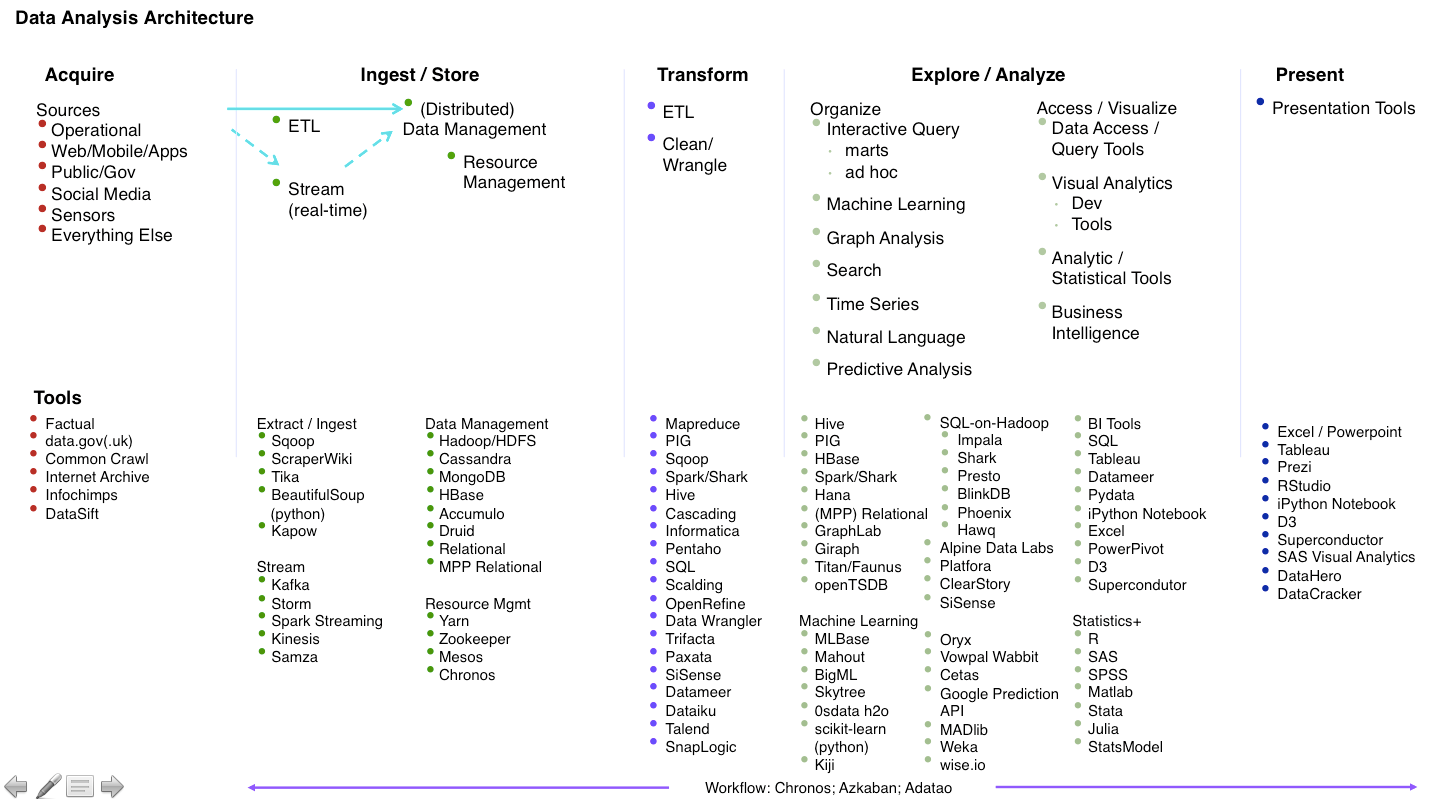
[aditude-amp id="medium2" targeting='{"env":"staging","page_type":"article","post_id":868639,"post_type":"story","post_chan":"none","tags":null,"ai":false,"category":"none","all_categories":"big-data,dev,","session":"B"}']
“The whole idea is letting you pull information together,” said Nathan. “If you’re solving an enormous industrial problem, you need this, but it’s out there written in FORTRAN. Now, we’re starting to see open-source start to go out to a lot of different verticals.”
Data scientists are, in the developer world, still a step or two behind.
“There are still a lot of people who use these old tools,” said Lorica. “Obviously, we need to pull them over to Python.”
“In the old school, you get your data, make a model, and you’re done,” said Nathan. “Now, you need multiple eyes on a project; I love to pair
[aditude-amp id="medium3" targeting='{"env":"staging","page_type":"article","post_id":868639,"post_type":"story","post_chan":"none","tags":null,"ai":false,"category":"none","all_categories":"big-data,dev,","session":"B"}']
[code][/code]
with people from other backgrounds. We have to be much smarter.”
Stay tuned for more from the DataBeat/Data Science Summit today in Redwood City, Calif.
VentureBeat's mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Learn More