
LinkedIn today announced that it is releasing a new key-value store — which is a category of database — under an open-source license. The software, which goes by the name PalDB, was designed to store what LinkedIn calls “side data” — essentially, data that’s needed for a certain very small piece of an entire application.
Side data has become important for LinkedIn. Here’s staff engineer Matthieu Monsch’s explanation of side data in a new blog post on PalDB:
Side data is the extra read-only data needed by a process to do its job. For instance, a list of stopwords used by a natural language processing algorithm is side data. Machine learning models used in machine translation, content classification or spam detection are also side data. When this side data becomes large it can be a bottleneck for applications depending on them.
There are other key-value stores that LinkedIn could use to store side data, including RocksDB and LevelDB, and LinkedIn could also have put side data in CSVs or JSON files, but as it has for other types of infrastructure technologies, LinkedIn chose to build its own. In the case of PalDB, LinkedIn optimized for speed, low memory usage, and simplicity.
LinkedIn is releasing benchmarks showing PalDB’s performance in comparison with that of RocksDB and LevelDB:
AI Weekly
The must-read newsletter for AI and Big Data industry written by Khari Johnson, Kyle Wiggers, and Seth Colaner.
Included with VentureBeat Insider and VentureBeat VIP memberships.
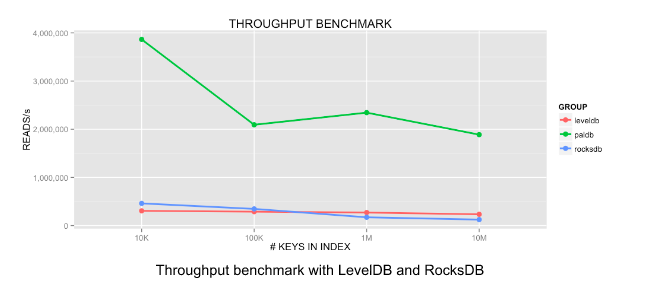
Above: Benchmarks for LinkedIn’s PalDB key-value store.
LinkedIn engineers now rely on PalDB for analytics and machine learning workloads, Monsch wrote.
PalDB is available on GitHub here.
VentureBeat's mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Learn More