At the Machine Learning @Scale conference that Facebook is hosting today in New York, Facebook is announcing that it’s enhancing the machine-generated photo descriptions that are available in screen readers like VoiceOver for iOS.
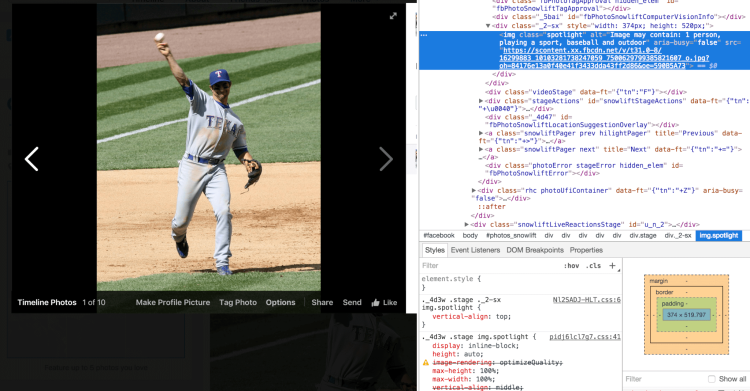
Now the descriptions — which you can check out without a screen reader using your browser’s Inspect Element feature on the web — will take into account the action that’s captured. For example, if a group of people are seen drumming in a photo, the caption might specify that people are playing instruments, as opposed to simply mentioning people and drums. Specifically there are 12 new actions that can be included in automatic-alt text for photos, Facebook director of applied machine learning Joaquin Quiñonero Candela wrote in a blog post.
That might not sound like a big change. But for people who lean heavily on screen readers to gather information about what’s happening — blind people, for example — the change will likely help them get a better understanding of what their Facebook friends are sharing in the News Feed. After all, the text that people include alongside the photos they post doesn’t always perfectly illustrate what’s going on.
Facebook first introduced automatic alt-text last April. It’s one of several ways Facebook is drawing on artificial intelligence. Apple, Google, Twitter, and other companies have also sought to use AI in their services. Microsoft is even working on automatically making image captions using AI in Word and PowerPoint.
At all of these companies, training AI systems requires data and, typically, clues that machines can use to get an idea of what to look for in new data. Here’s what Facebook did, in Quiñonero Candela’s words:
A considerable percentage of photos shared on FB include people, so we focused on providing automatic descriptions involving people. The AI team gathered a sample of 130,000 public photos shared on Facebook that included people. Human annotators were asked to write a single-line description of the photo, as if they were describing the photo to a visually impaired friend. We then leveraged these annotations to build a machine-learning model that can seamlessly infer actions of people in photos, to be used downstream for AAT.
But beyond that, Facebook has also thought up a new way to find photos that match end users’ search criteria.
“In other words, in a search for ‘black shirt photo,’ the system can ‘see’ whether there is a black shirt in the photo and search based on that, even if the photo wasn’t tagged with that information. Using Facebook’s automatic image classifiers, just like the ones used in the AAT example, you can imagine a scenario where someone could search through all the photos that his or her friends have shared to look for a particular one based on the image content instead of relying on tags or surrounding text,” Quiñonero Candela wrote.
That feature isn’t live yet, but once it is, it will provide a better way for you to find what you want on the vast graph of data that is Facebook. With the Graph Search effort introduced back in 2013, Facebook sought to let people use natural language to find exactly the right people; with visual search, it’s all about images. And from there, one could foresee Facebook surfacing relevant videos later on.
For more information see Quiñonero Candela’s full blog post.
VentureBeat's mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Learn More
