

LinkedIn is back at it, sharing with the world its tools to work with lots of different types of data. Today it’s providing insight into new data ingestion software it’s cobbled together to aggregate its own data with sources from outside the social-networking company, into a single tube of sorts.
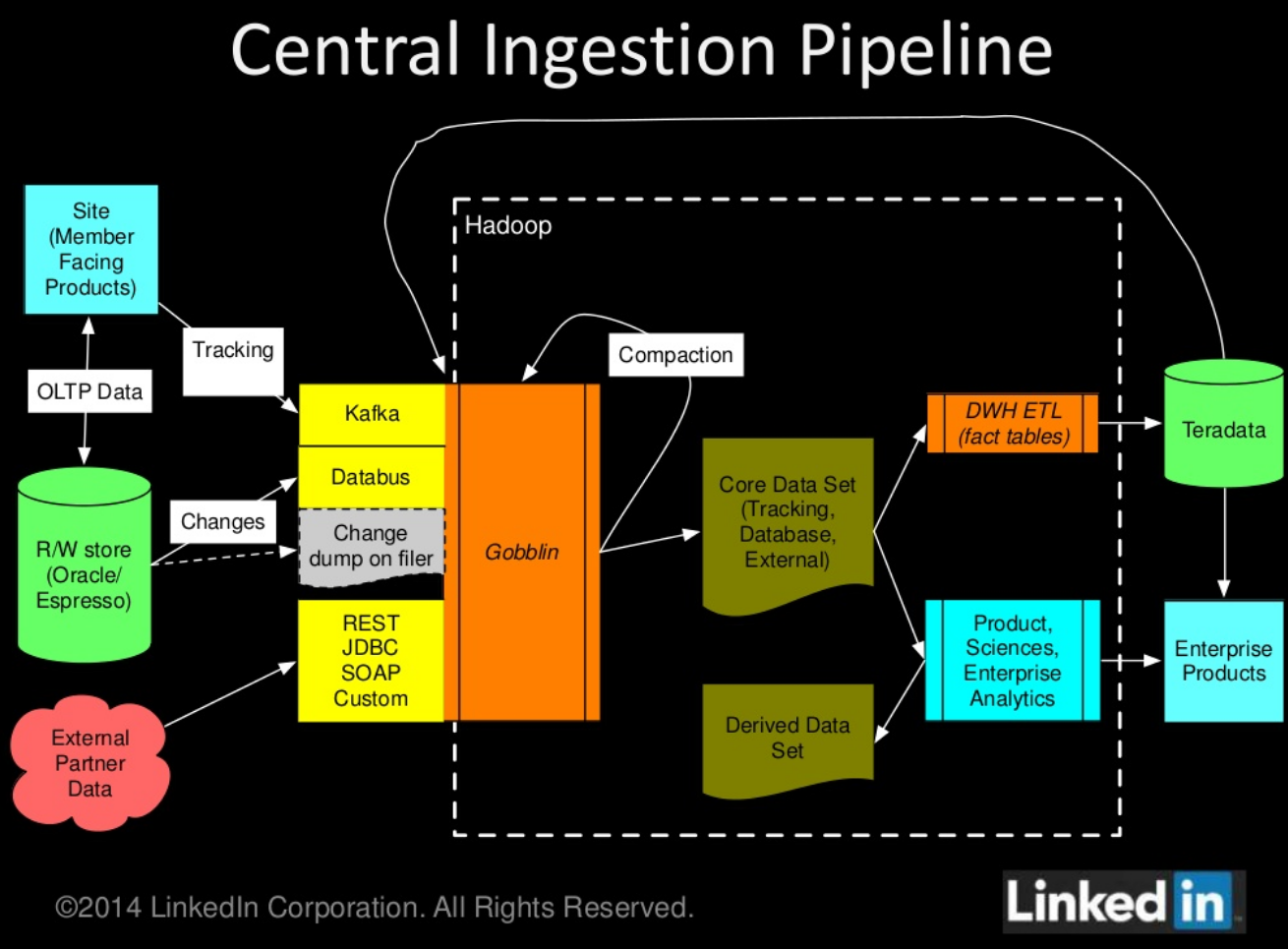
The software, dubbed Gobblin, hints at its supreme ability to gobble up bits, which data scientists can then use as they design new products and analyze website usage.
[aditude-amp id="flyingcarpet" targeting='{"env":"staging","page_type":"article","post_id":1613664,"post_type":"story","post_chan":"none","tags":null,"ai":false,"category":"none","all_categories":"big-data,cloud,dev,enterprise,social,","session":"A"}']LinkedIn won’t be keeping Gobblin private. Following in the steps of LinkedIn-initiated projects like Azkaban, Kafka, and Voldemort, Gobblin will become free for all to use under an open-source license sometime in the next few weeks, engineering manager Lin Qiao wrote in an engineering blog post that’s scheduled to go online today.
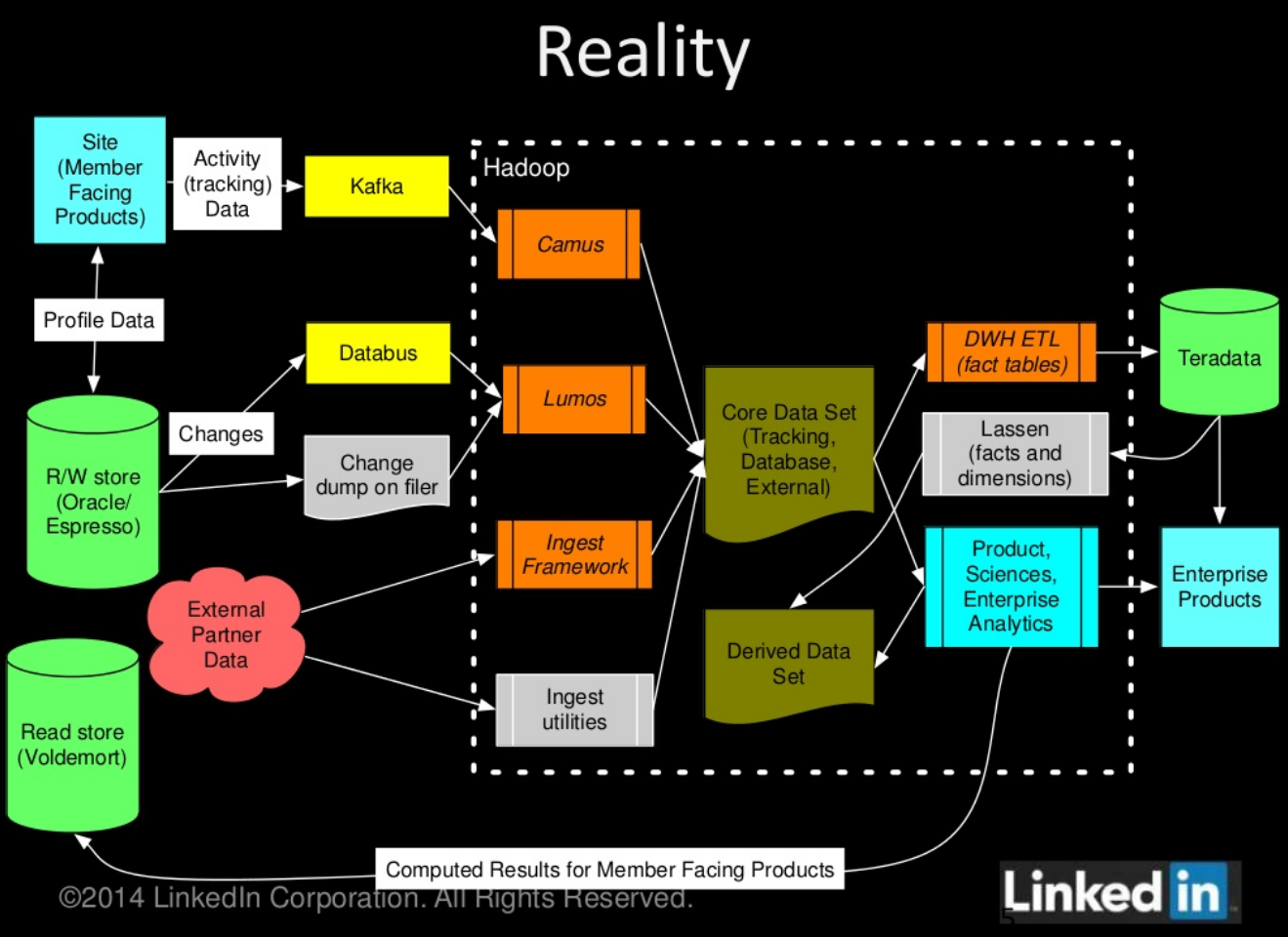
Meanwhile, LinkedIn is also shifting more of its data sets in the direction of Gobblin. Because in reality, even with LinkedIn’s previous work to simplify data engineering, managing all of the connections of data was still hard. Like any enterprise, the architecture is a mess.
AI Weekly
The must-read newsletter for AI and Big Data industry written by Khari Johnson, Kyle Wiggers, and Seth Colaner.
Included with VentureBeat Insider and VentureBeat VIP memberships.
“At one point, we were running more than 15 types of data ingestion pipelines and we were struggling to keep them all functioning at the same level of data quality, features, and operability,” as Qiao put it in the blog post.
Above: From a presentation Qiao gave at the QCon conference in San Francisco this month.
Gobblin simplifies things. It sits inside of LinkedIn’s substantive Hadoop cluster, where data transformation can be more economical than, say, LinkedIn’s expensive Teradata data warehouse. And Gobblin can handle a great lot of data, too, while integrating with widely accepted protocols and database types.
That way, data from a long list of sources can flow through one common pipeline. Think data from Salesforce.com, Twitter, and Facebook, alongside clickstream data, profile views, and social sharing of pages on LinkedIn. And don’t forget about data sources LinkedIn picks up in the course of making acquisitions. And because other companies deal with several data sources, Gobblin could well be adopted once it’s out in the open.
At least at LinkedIn, the tool has already come in handy.
“We’ve been getting better at gobbling large amounts of different kinds of datasets to feed our data hungry analysts,” Qiao wrote.
VentureBeat's mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Learn More